![[Network] HTTP/0.9](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2F7fH5a%2FbtsMt7dfp0P%2FAAAAAAAAAAAAAAAAAAAAAMucvisvb-VprAXS-Af7KGaiSc12BEeZBiHm2L3D6OOm%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DVixk00LtJ9Nzl328fOcoctn686c%253D)

🔖 HTTP 이해
HTTP를 제대로 이해하기 위해서는 현재의 사양을 단순히 학습하는 것보다, 이 프로토콜이 어떻게 발전해왔는지 그 역사적 맥락을 살펴보는 것이 도움이 된다. HTTP는 본질적으로 데이터를 주고받는 통신 프로토콜로, 메서드와 경로, 헤더, 바디, 그리고 상태 코드라는 요소들로 구성되어 있다.
HTTP는 1990년 최초 구현된 이후 꾸준히 진화해왔다. 최초의 HTTP/0.9는 단순히 HTML 문서를 주고받는 기능만 있었지만, 점차 폼 전송, 정보 갱신, 실시간 채팅 등 다양한 기능이 추가되면서 HTTP/1.0, HTTP/1.1, 그리고 HTTP/2로 발전했다. 특히 HTTP/0.9라는 이름은 HTTP/1.0이 등장한 후에 붙여진 것으로, 이는 1.0 이전 버전임을 나타내기 위함이었다.
🔖 웹 표준화
웹의 발전 과정에서 중요한 역할을 한 것이 RFC$_{Request \space for \space Comments}$다. RFC는 IETF가 관리하는 인터넷 표준 문서로, 처음에는 미국 국방 예산으로 개발된 네트워크 사양을 공개하기 위한 방편으로 시작되었다. 각각의 RFC는 고유한 번호를 가지고 필요에 따라 갱신되거나 폐기될 수 있다.


웹 기술의 표준화는 여러 조직이 담당하고 있다. 파일 타입 같은 공통 정보는 IANA가, 브라우저 관련 기능은 W3C가, 그리고 최근에는 WHATWG도 표준화 논의에 참여하고 있다. 또한 무선 LAN(IEEE), 자바스크립트(ECMA International), 동영상 코덱(ISO/IEC) 등 각 분야별로 다양한 표준화 기구가 존재한다.
웹의 초기 발전에는 CERN의 팀 버너스리가 개발한 최초의 웹 서버, NCSA의 로버트 매쿨이 만든 HTTPd(후에 아파치의 기원이 됨), 그리고 마크 앤드리슨의 NCSA 모자이크 브라우저가 중요한 역할을 했다. 이후 넷스케이프는 자바스크립트와 SSL 등 모던 웹의 기술들을 개발했고, 이들은 차후에 웹 표준으로 자리잡게 되었다.
🔖 HTTP/0.9의 기본 구조와 동작
HTTP/0.9는 매우 단순한 구조를 가진 프로토콜이었다. 기본적으로 텍스트로 된 웹 페이지의 경로를 서버에 전달하고, 해당 페이지를 받아오는 것이 전부였다. 이런 동작은 현재 curl 커맨드를 통해 시뮬레이션해볼 수 있지만, 정확한 재현은 어렵다. HTTP/0.9는 현재 프로토콜과 하위 호환성이 없기 때문에, 대신 HTTP/1.0을 사용해 유사한 동작을 살펴볼 수 있다.

HTTP/0.9의 기본 동작은 단순했다. 웹사이트의 페이지를 서버에 요청하면, 응답으로 웹사이트의 내용을 받아와 Hyper Text Transfer Protocol이라는 이름 그대로를 반영한다. 통신이 완료되면 서버와의 연결은 자동으로 종료된다. 요청 시에는 호스트 이름(ex, localhost)이나 IP 주소, 그리고 포트 번호를 지정한다. 포트 번호를 생략하면 기본값인 80번이 사용된다.
🔖 초기 웹의 검색 기능
당시 웹의 중요한 특징 중 하나는 'form'과 검색 기능이었다. HTML 문서에서 <isindex> 태그를 사용하면 텍스트 입력 필드가 생성되어 검색이 가능했다. 검색 시에는 URL 끝에 물음표(?)와 검색어(+로 구분)를 붙여 요청을 보냈다.
http://example.com/?search+word
이런 URL 기반 검색 방식인 <isindex> 태그가 현재는 사라졌지만, 검색 키워드를 URL에 포함시키는 기본 개념은 현재까지도 유지되고 있다. curl에서는 검색 요청을 아래 코드와 같이 구현할 수 있다.
$ curl --http1.0 --get --data-urlencode "search word" http://localhost:5173
여기서 --get 옵션(-G로도 사용 가능)과 --data-urlencode는 URL에 검색 쿼리를 추가해 공백이나 특수 문자를 적절하게 인코딩한다. 위 처럼 초창기 HTTP의 단순했던 구조는 이후 HTTP/1.0에서 더 발전하게 된다.
🔖 HTTP/0.9에서 1.0으로의 과도기
HTTP/0.9는 '브라우저가 문서를 요청하면, 서버는 데이터를 반환한다'라는 웹의 기본 뼈대는 이미 완성되어 있었지만, 여러 제약사항이 있었다. HTML 문서만 전송 가능했고, 콘텐츠 형식을 서버가 전달할 수 없었다. 클라이언트는 검색 외의 요청을 보낼 수 없었다. 또한 문서의 생성, 갱신, 삭제도 불가능했고, 요청과 응답의 정상 여부를 확인할 방법도 없었다.
1990년에 문서화된 0.9 버전은 2년 후 전자메일과 뉴스그룹 프로토콜의 기능을 도입하며 크게 업데이트되었다. curl 커맨드의 상세 정보 옵션(-v)으로 확인할 수 있다.

1992년 버전에서는 단순한 버전(0.9 호환)과 전기능 버전(1.0과 유사)이라는 두 가지 요청 형식이 도입되었다.
- 요청(>로 시작되는 행) 측면의 변화
- GET과 같은 메서드 추가
- HTTP 버전 정보 포함
- Host, User-Agent, Accept 등의 헤더 추가
- 응답(<로 시작되는 행) 측면의 변화
- HTTP 버전과 상태 코드가 응답 시작 부분에 포함
- 요청과 동일한 형식의 헤더 포함
🔖 전자메일 도입
HTTP의 헤더 시스템은 인터넷 이전 시대부터 사용되던 전자메일 시스템에서 그 기원을 찾을 수 있다. 현재 우리가 사용하는 전자메일 표준은 1982년 RFC 822에서 규격화되었지만, 실제 이런 시스템을 사용하기 시작한 것은 인터넷의 전신인 ARPANET에서 1970년대부터다. 특히 헤더의 기본 형태는 1977년 RFC 733에서 이미 확립되어 있었다.
전자메일의 기본 구조를 살펴보면 다음과 같은 예시를 볼 수 있다. Gmail을 통해 나에게 메일을 보내 본 것이다. 만약 이런 식으로 메일을 보고 싶다면, 메일에 들어간 다음 원본 보기를 통해 이런 형식으로 볼 수 있다.

이러한 헤더는 "필드명: 값" 형식으로 구성되고 각 헤더는 개별 행에 작성된다. 헤더와 본문 사이에는 반드시 빈 줄이 하나 존재한다. 헤더 이름은 대소문자를 구분하지 않고 프로그래밍 환경에서는 일반적으로 처리의 편의성을 위해 정규화된다. 헤더에는 발신지, 메일 형식 버전, 전송 시간, 발신자 정보, 제목, 콘텐츠 형식, 문자 인코딩 등 메시지의 메타데이터가 모두 포함된다.
HTTP에서의 헤더 활용
HTTP는 이런 전자메일의 헤더 시스템을 그대로 도입했다. HTTP 헤더는 서버와 클라이언트 간의 추가 정보, 지시사항, 명령 등을 전달하는 데 사용된다. 주요 헤더들은 다음과 같다.
- 클라이언트가 서버로 보내는 헤더
- User-Agent: 클라이언트 애플리케이션을 식별하는 문자열 (예: curl/7.48.0)
- Referer: 현재 요청 이전에 방문한 페이지의 URL
- Authorization: 클라이언트 인증 정보 (Basic/Digest/Bearer 등의 표준 형식 사용)
- 서버가 클라이언트로 보내는 헤더
- Content-Type: MIME 타입을 사용한 파일 형식 지정
- Content-Length: 응답 본문의 크기
- Content-Encoding: 압축 방식
- Date: 문서 생성/수정 날짜
추가로 'X-'로 시작하는 헤더는 각 애플리케이션이 자유롭게 사용할 수 있는 커스텀 헤더로 규정되어 있다. 등록된 헤더는 IANA에서 찾아볼 수 있다.
MIME 타입
MIME$_{Multipurpose \space Internet \space Mail \space Extensions}$ 타입은 1992년 RFC 1341에서 처음 등장한, 파일의 종류를 구별하기 위한 식별자 체계다. 원래 전자메일을 위해 개발되었지만 현재는 웹을 포함해 인터넷 프로토콜에서 광범위하게 사용되고 있다.
초기 컴퓨터 시스템들은 각자 다른 방식으로 파일 형식을 구분했다. Windows는 파일 확장자(.txt, .doc 등)를 사용했고, Mac OS는 'resource fork'라는 메타데이터 시스템을 활용했다. 파일을 더블클릭했을 때 어떤 프로그램으로 열지를 결정하는 데 사용되었다.
모던 웹 환경에서 MIME 타입은 아래처럼 사용된다.
Content-Type: text/html; charset=utf-8
브라우저는 이 정보를 바탕으로 콘텐츠를 처리한다.
- HTML 파일은 웹 페이지로 렌더링
- 이미지는 화면에 표시
- PDF 파일은 다운로드 또는 내장 뷰어로 표시
사진과 동영상의 경우 브라우저나 환경에 따라 이용할 수 있는 포맷이 일부 다르다. 클라이언트와 서버는 지원 가능한 형식에 대해 협상$_{content \space negotiation}$을 통해 최적의 형식을 선택할 수 있다.
Content-Type
브라우저는 기본적으로 Content-Type 헤더의 MIME 타입에 따라 파일의 종류를 식별한다. 하지만 파일 확장자가 항상 실제 콘텐츠 타입을 정확히 반영하는 것은 아니다. 예를 들어, 과거 널리 사용되던 CGI 기반 접속 카운터의 경우를 보자.
<img src="/cgi-bin/counter.cgi">이 경우 .cgi 확장자만으로는 실제 출력될 콘텐츠의 타입을 알 수 없다. 실제로는 CGI 프로그램이 Content-Type: image/gif와 같은 헤더를 생성해 브라우저가 이미지를 올바르게 표시할 수 있었다.
콘텐츠 스니핑의 위험성
Internet Explorer는 콘텐츠 스니핑$_{content \space sniffing}$이라는 기능을 통해 MIME 타입과 관계없이 파일 내용을 분석하여 형식을 추측하려 시도한다. 사용자 편의성을 높이는 것처럼 보일 수 있지만, 아래와 같은 이유로 심각한 보안 위험을 초래할 수 있다.
- text/plain으로 지정된 파일에 HTML과 JavaScript가 포함된 경우, 브라우저가 이를 실행할 수 있음
- XSS$_{Cross-Site \space Scripting}$ 공격의 위험성을 높임
이러한 위험을 방지하기 위해, 모던 웹 서버는 다음 헤더를 사용하여 콘텐츠 스니핑을 명시적으로 비활성화한다.
X-Content-Type-Options: nosniff
HTTP와 전자메일 헤더의 차이점
HTTP와 전자메일은 비슷한 헤더 구조를 공유하고 있다. 두 프로토콜 모두 '헤더 + 본문' 형태의 기본 구조를 사용하지만, HTTP는 전자메일과 달리 추가적인 요소들을 포함한다. HTTP 요청의 경우 첫 줄에 메서드와 경로 정보가 추가되고 HTTP 응답에서는 첫 줄에 상태 코드가 포함된다.
세부적인 규칙에서도 차이가 있다. 전자메일에서는 긴 헤더를 위한 줄바꿈 규칙이 정의되어 있는 반면, HTTP는 RFC 7230 이후로는 헤더의 줄바꿈을 권장하지 않는다. 응답 분할 공격이라는 보안 위험을 방지하기 위해서다. 또한 다국어 지원 측면에서도 차이가 있다. 전자메일은 초기에 영어권 사용만을 고려했다가 후속 표준을 통해 다국어 지원을 추가하면서 더 복잡한 규칙이 생겨났다.
결국 HTTP는 전자메일의 헤더 시스템을 기반으로 삼되, 웹이라는 새로운 환경의 요구사항에 맞춰 최적화되고 보안이 강화된 프로토콜로 발전했다고 볼 수 있다.
🔖 뉴스그룹 도입
뉴스그룹(또는 유즈넷)은 인터넷 이전 시대의 주요 커뮤니케이션 플랫폼이었다. 대규모 전자 게시판의 형태로, 주제별로 그룹이 만들어져 토론이 이루어졌다. 많은 프로그래밍 언어들이 이 플랫폼을 통해 첫 공개되었는데, 예를 들어 Ruby는 fj.comp.langs.misc 그룹에서, Python은 1991년 alt.sources 그룹에서 처음 공개되었다.
뉴스그룹은 분산 아키텍처를 기반으로 했다. 서버들은 마스터/슬레이브 구조로 연결되어 있었으며, NNTP(Network News Transfer Protocol, RFC 977, 1986년)를 사용해 통신했다. HTTP/0.9보다 5년, HTTP/1.0보다 10년이나 앞선 프로토콜이었다. 뉴스그룹에서의 메서드로는 그룹 목록 취득(LIST), 헤더 취득(HEAD), 기사 취득(BODY), 투고(POST) 등이 있었다.
HTTP는 뉴스그룹으로부터 메서드와 상태 코드라는 두 가지 요소를 도입했다. HTTP/1.0에서 사용되는 메서드는 객체 지향 프로그래밍의 메서드와 유사하게, 지정된 주소의 리소스에 대한 조작을 서버에 지시한다. 가장 기본적인 메서드로는 서버에 헤더와 콘텐츠를 요청하는 GET, 헤더만 요청하는 HEAD, 새로운 문서를 투고하는 POST가 있다.
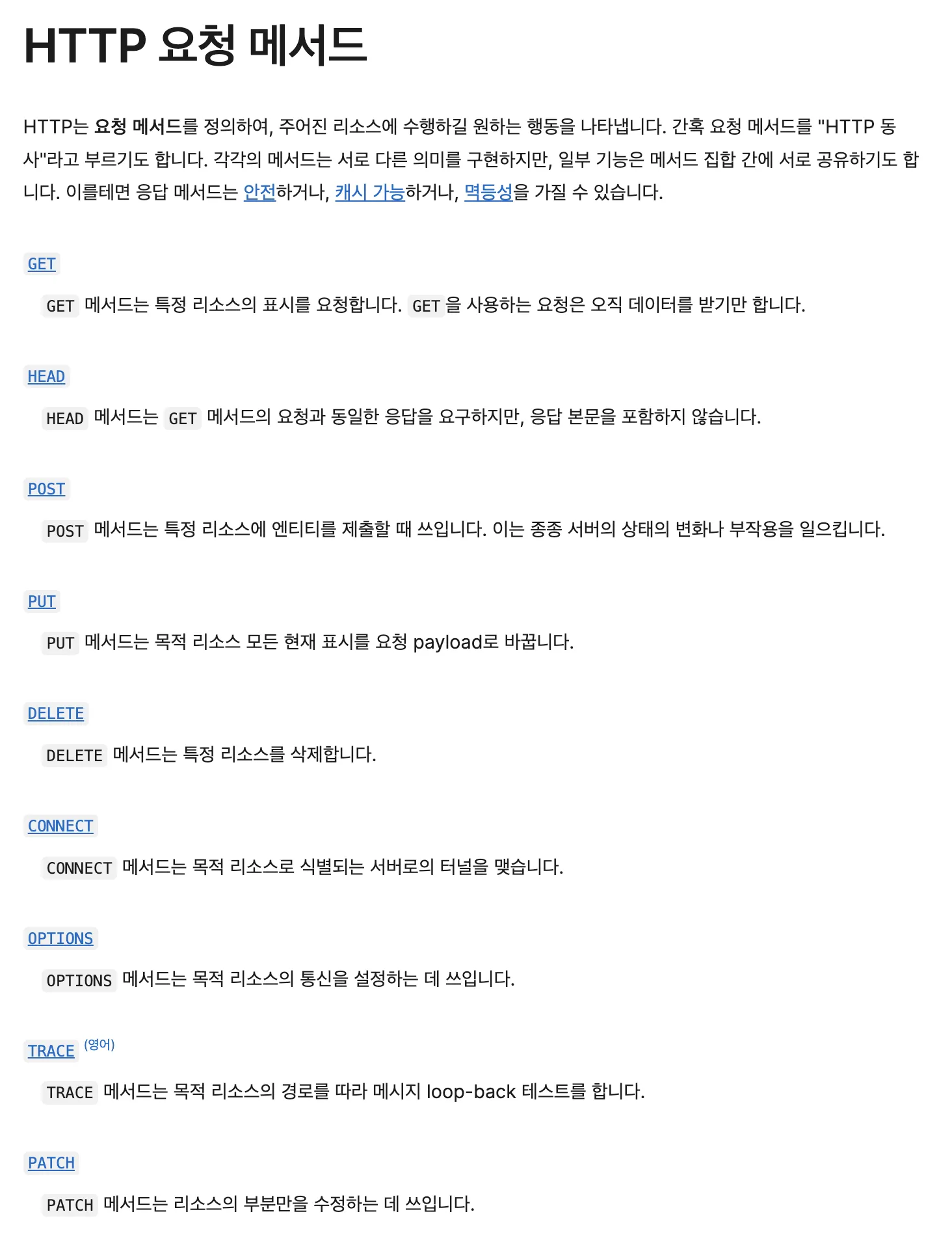
추가로 PUT과 DELETE 메서드도 있었는데, 이들은 HTTP/1.0에서 필수가 아닌 선택적 기능이었다. PUT은 이미 존재하는 URL의 문서를 갱신하고, DELETE는 지정된 URL의 문서를 삭제하는 기능을 했다. 실제로 브라우저가 이러한 메서드들을 표준 기능으로 사용할 수 있게 된 것은 한참 후의 일로, JavaScript의 XMLHttpRequest가 지원되면서부터였다. HTML의 form 요소는 GET과 POST만을 지원했다.
상태 코드는 서버의 응답 상태를 나타내는 3자리 숫자로, 크게 5가지 카테고리로 구분된다. 100번대는 처리가 계속 진행 중임을 나타내는 특수한 용도로 사용된다. 200번대는 요청이 성공적으로 처리되었음을 의미하며, 가장 흔히 볼 수 있는 것이 정상 종료를 나타내는 200 OK다. 300번대는 리다이렉트나 캐시 사용과 같은 서버의 추가 지시를 나타내며, 이는 오류가 아닌 정상 처리의 범주에 속한다. 400번대는 클라이언트의 요청에 오류가 있음을, 500번대는 서버 내부에서 오류가 발생했음을 나타낸다.
🔖 리다이렉트
HTTP에서 300번대 상태 코드의 일부는 서버가 브라우저에게 리다이렉트를 지시하는 용도로 사용된다. 대부분의 리다이렉트는 Location 헤더를 통해 새로운 위치를 클라이언트에게 전달한다. 리다이렉트는 성격에 따라 분류해볼 수 있다.
- 영구적 리다이렉트 (301/308)
- 페이지가 완전히 다른 위치로 이동했을 때 사용
- 도메인 이전, HTTP에서 HTTPS로의 전환 등에 활용
- 검색 엔진은 이전 페이지의 평가를 새 페이지로 이전
- 구글은 특히 301을 권장
- 임시 리다이렉트 (302/307)
- 일시적인 페이지 이동에 사용
- 모바일 전용 사이트 리다이렉션
- 시스템 점검 페이지로의 전환 등
- 기타 리다이렉트 (303)
- 요청된 페이지에 직접적인 콘텐츠가 없을 때 사용
- 주로 로그인 후 원래 페이지로 돌아가는 등의 상황에 활용
curl에서는 -L 옵션을 사용해 리다이렉트를 처리할 수 있다. 기본적으로 최대 50회까지 리다이렉트를 따라가며, --max-redirs 옵션으로 이 제한을 조정할 수 있다. 301, 302, 303 상태 코드의 경우 GET 이외의 메서드는 GET으로 변경되는 것이 기본이나, --post301, --post302, --post303 옵션으로 방지할 수 있다.
$ curl -L https://www.google.com
HTTP/1.0에서 1.1로 발전하면서 리다이렉트 사양도 변화했다. RFC 7231에서는 301처럼 메서드 변경이 허용되었고, 메서드 변경에 허가가 필요한 307과 308이 새롭게 추가되었다. 리다이렉트 횟수 제한은 RFC 2616에서 공식적으로는 없어졌지만, 실제 구현에서는 제한을 두는 것이 일반적이다.
리다이렉트의 주요 단점은 성능 저하다. 특히 다른 서버로의 리다이렉트는 TCP 연결 설정과 HTTP 통신이 추가로 필요하므로, 구글은 리다이렉트 횟수를 5회 이하, 가능하면 3회 이하로 제한할 것을 권장한다.
마지막으로 300 Multiple Choices라는 특별한 상태 코드도 존재하지만, 실제로는 거의 사용되지 않는다. RFC 7231에서는 이를 200 OK나 406 Not Acceptable로 대체하고 Link 헤더를 통해 대안을 제시하는 방법을 권장한다.
🔖 URL
URL$_{Uniform \space Resource \space Locator}$은 RFC 1738에서, 상대 URL은 RFC 1808에서 정의되었다. HTTP/1.0보다 앞선 시기의 문서로 HTTP 프로토콜의 발전을 예상하고 미리 규격화되었다.
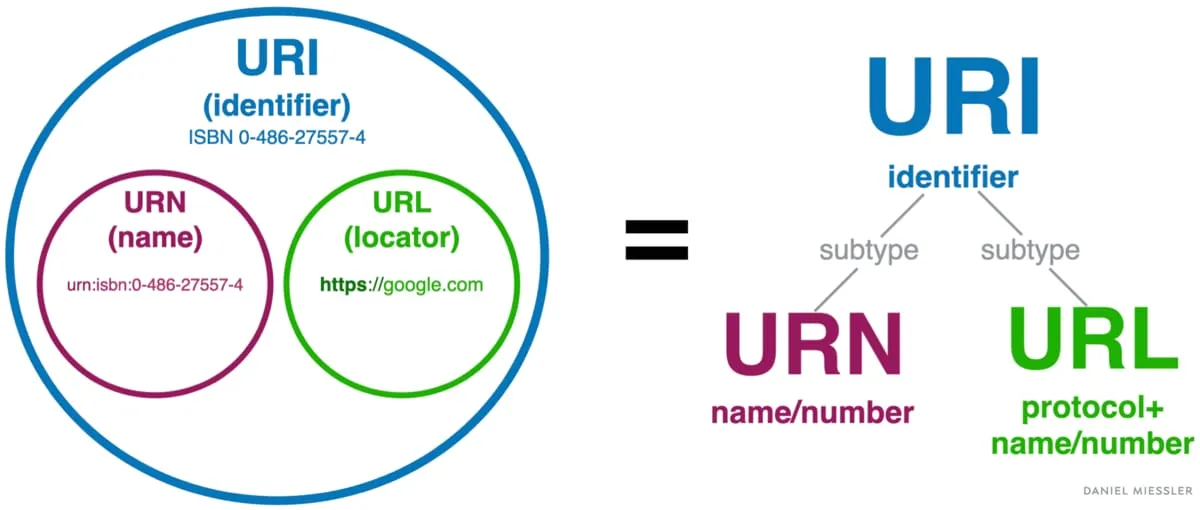
URI$_{Uniform \space Resource \space Identifier}$는 URL과 URN$_{Uniform \space Resource \space Name}$을 포함하는 상위 개념이다. URL이 리소스의 위치를 지정하는 주소라면, URN은 리소스의 고유 이름을 나타낸다.
URL: <http://example.com/book/123>
URN: urn:isbn:0-123-45678-9
웹에서는 대부분 URL을 사용하며, URN은 거의 사용되지 않는다. RFC 3305에서 URL은 관용적 표현으로, URI가 공식 표기가 되었지만 실제로는 URL이라는 용어가 더 널리 사용되고 있다.
일반적인 URL은 아래와 같은 구성요소를 가진다.
scheme://user:password@host:port/path#fragment?query- 스키마$_{scheme}$: http, https, mailto, ftp 등 통신 프로토콜을 지정
- 사용자명과 비밀번호: 주로 FTP에서 사용되었으나, 보안상의 이유로 현재는 거의 사용되지 않음
- 호스트명$_{host}$: 서버의 도메인 이름이나 IP 주소
- 포트$_{port}$: 서버의 접속 포트 (HTTP는 80, HTTPS는 443이 기본값)
- 경로$_{path}$: 서버 내의 리소스 위치
- 프래그먼트$_{fragment}$: 페이지 내 특정 섹션을 가리키는 앵커
- 쿼리$_{query}$: 추가적인 파라미터 정보
URL은 단순한 주소 지정 외에도 사용자가 읽을 수 있는 의미있는 정보를 전달하는 역할도 한다. 예를 들어 http://www.example.com/books/9784873114958/ 같은 URL은 경로 구조를 통해 웹사이트의 구조와 목적을 대략적으로 이해할 수 있게 해준다.
URL의 길이에 대한 공식적인 제한은 없지만, Internet Explorer의 2083자 제한으로 인해 2000자가 일반적인 기준이 되었다. HTTP/2에서는 과도하게 긴 URL에 대해 414 URI Too Long 상태 코드가 추가되었다.
2003년 RFC 3492에서는 국제화 도메인 이름(IDN)을 위한 퓨니코드(Punycode) 인코딩이 도입되어, 비영어 문자를 포함하는 도메인 이름의 사용이 가능해졌다. https://내도메인.한국/과 같은 대표적인 예시가 있다.
🔖 바디
HTTP/1.0에서는 0.9 버전과 달리 요청과 응답 모두에 헤더와 바디가 포함될 수 있게 되었다. 전자메일과 유사한 구조를 가지는데, 헤더와 바디는 빈 줄로 구분된다.
헤더1: 헤더값1
헤더2: 헤더값2
Content-Length: 바디의 바이트 수
[바디 내용]
HTTP 응답의 바디는 단순하다. 한 번의 응답에 하나의 파일만 반환되고 Content-Length 헤더로 지정된 바이트 수만큼만 읽으면 된다. 요청에서 폼이나 XMLHttpRequest를 통해 데이터를 전송할 때도 유사한 구조가 사용된다.
바디 데이터는 압축될 수 있고 이 경우 Content-Encoding 헤더로 압축 알고리즘이 지정된다. Content-Length는 항상 실제 전송되는 데이터의 크기(압축 후 크기)를 나타낸다.
curl 명령어로 바디를 전송할 때 사용할 수 있는 주요 옵션들은 아래와 같다.
d,-data,-data-ascii: 텍스트 데이터 전송-data-urlencode: URL 인코딩이 필요한 텍스트 데이터-data-binary: 바이너리 데이터 전송T또는d@파일명: 파일에서 데이터 읽어서 전송
예를 들어 JSON 데이터를 전송할 경우 이렇게 작성하면 된다.
curl -d '{"hello": "world"}' -H "Content-Type: application/json" http://localhost:5173
HTTP의 GET 메서드는 일반적으로 바디를 포함하지 않지만, 기술적으로는 가능하다. RFC 7231에 따르면 GET, HEAD, DELETE, OPTIONS, CONNECT 메서드는 바디를 포함할 수 있으나, 서버가 이를 거부할 수 있다. 단, TRACE 메서드는 명시적으로 바디 포함이 금지되어 있다.
어떤 HTTP 요청 메시지라도 메시지 바디 포함이 허용되며 이를 염두에 두고 해석할 필요가 있습니다. 그러나 서버는 GET 의 바디가 있어도 요청에 대해 뭔가 의미를 얻지 못하게 제한됩니다. 해석 여부와 메서드의 시맨틱스는 별개입니다. GET 과 함께 바디를 보낼 수 있지만, 그렇게 하는 것이 결코 유용하진 않습니다.
로이 필딩 (HTTP/1.1의 저자 중 한 명)
서버는 GET 요청의 바디를 읽을 수는 있지만, 요청 처리 시 무시해야 한다는 것이 일반적인 원칙이다.
🔖 마무리
HTTP/1.0은 1996년 RFC 1945로 공식 정의되었다. 과거 다양한 통신 시스템의 장점을 수용하면서도 단점을 보완한, 단순하면서도 효율적인 프로토콜로 자리잡았다. HTTP는 다음 네 가지 기본 데이터 구조를 중심으로 설계되었다.
- 메서드와 경로: 리소스에 대한 작업을 지정
- 헤더: 메타데이터와 제어 정보를 전달
- 바디: 실제 데이터 내용을 전송
- 상태 코드: 요청 처리 결과를 표시
이러한 기본 구조는 현재의 HTTP/2에 이르기까지 근본적으로 변화하지 않았고 HTTP와 웹 브라우저의 동작을 이해하는 데 필요한 요소들이다.
curl 커맨드는 HTTP 요소들을 직접 다룰 수 있게 해주는 강력한 도구다. 웹 서버 개발 시 디버깅을 자동화하거나, 상세한 동작을 단계별로 분석하는 데 활용할 수 있다. HTTP/1.0은 위와 같은 기본 요소들을 바탕으로 더 복잡한 고수준의 기능들을 구현했다.
references
https://www.yes24.com/Product/Goods/71849916
'CSE > 네트워크 (network)' 카테고리의 다른 글
| [Network] Fairness (0) | 2025.04.20 |
|---|---|
| [Network] TCP Congestion control (0) | 2025.04.20 |
| [Network] HTTP와 HTTPS (3) | 2025.02.04 |
| [Network] OSI Model과 7 Layer 별 장비 (1) | 2025.01.11 |
| TCP/IP 프로토콜 4판 - 연습문제 15장 (2) | 2024.01.12 |
컴퓨터 전공 관련, 프론트엔드 개발 지식들을 공유합니다. React, Javascript를 다룰 줄 알며 요즘에는 Typescript에도 관심이 생겨 공부하고 있습니다. 서로 소통하면서 프로젝트 하는 것을 즐기며 많은 대외활동으로 개발 능력과 소프트 스킬을 다듬어나가고 있습니다.
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[Network] Fairness](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcgOs7S%2FbtsNsm2cRXU%2FAAAAAAAAAAAAAAAAAAAAAE1i1BTvYS2HMjRrWf_14TfeQxaLhVNaZsjgk6Iq64bD%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DNy8s0XmiyFK6n1xftGCtm2xYQm4%253D)
![[Network] TCP Congestion control](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FyEK80%2FbtsNtf84bUg%2FAAAAAAAAAAAAAAAAAAAAANO1V8KtuGGHjKpjEU_OnroD5m7Nclmr9MrlmFytTSLt%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DSn2hJ%252FkNDQqbOoazL4fgGKRVBmY%253D)
![[Network] HTTP와 HTTPS](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FdiOdrN%2FbtsL7vTmSKe%2FAAAAAAAAAAAAAAAAAAAAAJH9VRGOpHHfLAC9E05SR4NG8OadqcL1St-EkFyv7CBo%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3D2j%252Bg7VsGowp9CjJzQw80dpV1cVM%253D)
![[Network] OSI Model과 7 Layer 별 장비](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcnEMAv%2FbtsLJcn0jw1%2FAAAAAAAAAAAAAAAAAAAAAM8urZtIO4euiMPqanPNyj0DSWDc-jGxrliJgdS2OcLS%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DHnqTwEf%252FZVz%252FQYevmqj9U%252B0a0sA%253D)