![[JavaScript] V8 엔진](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FSoO2B%2FbtsL4Kb8JXT%2FOGiI7YKfpBXop2fvpKtgkK%2Fimg.jpg)

JavaScript 엔진의 등장
웹 브라우저 전쟁과 성능 경쟁
2008년 이전의 JavaScript는 웹에서 단순한 스크립트 언어로 사용됐다. 브라우저들은 인터프리터로 JavaScript를 실행했고, 성능은 중요한 고려 사항이 아니었다.
하지만 웹 애플리케이션이 복잡해지면서 상황이 바뀌었다. Gmail과 Google Maps 같은 웹 애플리케이션이 등장하면서 JavaScript 성능이 브라우저의 경쟁력이 됐다. 구글은 기존 JavaScript 엔진의 한계를 확인했다. 파이어폭스의 SpiderMonkey와 인터넷 익스플로러의 Chakra로는 복잡한 JavaScript 애플리케이션을 처리하기 어려웠다.
브라우저 전쟁은 JavaScript 생태계를 변화시켰다. 브라우저 개발사들은 JavaScript 엔진 개선에 투자했다. 모질라는 TraceMonkey를 만들었고, 애플은 JavaScriptCore를 발전시켰다.
변화의 중심에는 구글의 크롬 브라우저와 V8 엔진이 있었다. V8은 기존 엔진과 다른 방식을 선택했다. JIT 컴파일을 도입해 네이티브 코드에 가까운 성능을 보여줬다. V8의 강력한 성능과 확장성은 Node.js의 기반이 되어, JavaScript가 서버 환경으로 확장되는 계기가 됐다.
Google Chrome과 V8의 탄생
구글은 2008년 9월 Chrome 브라우저와 함께 V8 JavaScript 엔진을 공개했다. 당시 브라우저들은 JavaScript를 단순한 스크립트 언어로 취급했고, 대부분 인터프리터 방식으로 실행했다. Chrome은 각 탭을 별도의 프로세스로 실행하는 멀티 프로세스 아키텍처를 도입했고, V8은 이 구조에서 JavaScript를 실행하는 핵심 엔진이 됐다.
초기 V8은 Full-codegen과 Crankshaft라는 두 개의 컴파일러로 구성됐다.

Full-codegen은 JavaScript 코드를 빠르게 기계어로 변환하는 베이스라인 컴파일러였고, Crankshaft는 자주 실행되는 코드를 더 효율적으로 최적화하는 컴파일러였다. 이 구조는 2010년부터 2017년까지 V8의 성능을 이끌었다.
하지만 JavaScript가 발전하면서 이 구조의 한계가 드러났다. Crankshaft는 JavaScript의 일부 기능만 최적화할 수 있었고, 9개의 CPU 아키텍처마다 만 줄 이상의 코드를 따로 관리해야 했다. 2017년에 V8 팀은 Ignition 인터프리터와 TurboFan 컴파일러로 구성된 새로운 파이프라인을 도입했다.


TurboFan은 컴파일러 최적화 단계를 계층화해서 아키텍처별 코드를 한 번만 작성하면 되게 했고, Ignition의 바이트코드 핸들러도 TurboFan을 통해 생성하게 했다. 이로써 V8은 플랫폼별 코드 관리 부담을 크게 줄일 수 있었다.

V8이 JavaScript 생태계에 미친 영향
이전까지 JavaScript는 브라우저에서 간단한 동작을 처리하는 용도로만 여겨졌지만, V8의 성능 향상으로 복잡한 웹 애플리케이션 개발이 가능해졌다. Gmail이나 Google Maps 같은 대규모 웹 애플리케이션이 그 예다.
V8로 가장 큰 영향을 주었다고 볼 수 있는 것은 Node.js의 탄생이다. 2009년 Ryan Dahl은 V8의 뛰어난 성능과 C++ 기반 확장성을 활용해 서버 사이드 JavaScript 런타임인 Node.js를 만들었다. Node.js는 JavaScript를 브라우저 밖에서도 사용할 수 있게 했고, npm(Node Package Manager)을 통해 거대한 패키지 생태계가 만들어졌다.
다른 JavaScript 엔진들도 V8의 영향을 받았다. Mozilla의 SpiderMonkey, Microsoft의 Chakra, Apple의 JavaScriptCore 모두 JIT 컴파일 도입과 같은 V8의 혁신을 따랐다.
V8의 핵심 아키텍처
인터프리터와 컴파일러의 만남
전통적으로 프로그래밍 언어는 인터프리터 방식이나 컴파일러 방식 중 하나를 선택해 실행됐다. 인터프리터는 코드를 한 줄씩 바로 실행하기 때문에 실행 시작이 빠르지만 최적화 기회가 적어 전반적인 실행 속도가 느렸다. 컴파일러는 코드 전체를 기계어로 변환하기 때문에 초기 변환에 시간이 걸리지만 최적화된 코드를 생성할 수 있었다.
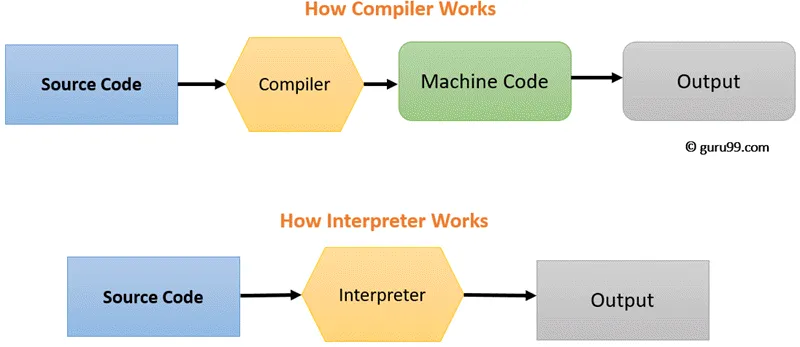
V8은 이 두 가지 방식의 장점을 모두 취했다. 2015년에 도입한 TurboFan JIT 컴파일러는 이전보다 더 발전된 최적화 기능을 제공했다. JavaScript 코드는 처음에는 최적화되지 않은 형태로 TurboFan에 전달되고, 여러 단계의 최적화를 거쳐 최종적으로 기계어로 변환된다. TurboFan은 이 과정에서 레이어드 아키텍처를 도입해 JavaScript 언어 레벨과 CPU 아키텍처 레벨을 깔끔하게 분리했다.

참고로 V8은 이후로도 계속 발전해서 JIT-less 모드(2019) 나 Maglev JIT(2023) 같은 새로운 실행 방식을 도입했지만, 이 글에서는 V8의 Ignition과 TurboFan을 중심으로 설명하는 것이 목적이므로 자세한 내용은 생략하겠다.
이 조합은 웹 애플리케이션의 특성과 잘 맞았다. 웹 페이지를 열 때는 많은 JavaScript 코드가 처음 실행되므로 인터프리터로 빠르게 시작하고, 사용자와 상호작용하는 중요한 코드는 컴파일러로 최적화해 빠르게 실행할 수 있었다.
Ignition 인터프리터
V8은 모든 JavaScript 코드를 먼저 Ignition이라는 인터프리터로 실행한다. Ignition은 JavaScript 코드를 바이트코드로 변환하고 이를 해석하면서 실행한다. 이전의 Full-codegen 컴파일러는 모든 코드를 즉시 기계어로 변환했지만 메모리를 많이 사용한다는 단점이 있었다.
Ignition은 크게 두 가지 역할을 한다. 첫째는 코드를 빠르게 실행하는 것이다. 바이트코드는 기계어보다 크기가 작아 메모리를 적게 사용하면서도, 인터프리터가 효율적으로 실행할 수 있는 형태다. 둘째는 코드의 실행 정보를 수집하는 것이다. Ignition은 코드가 실행되는 동안 타입 정보나 객체의 구조 같은 데이터를 수집해 TurboFan에 전달한다.
참고로 바이트코드는 실제 기계어는 아니지만 인터프리터가 실행하기 쉽게 최적화된 중간 형태의 코드를 말한다.
TurboFan 컴파일러
TurboFan은 V8의 최적화 컴파일러다. Ignition이 코드를 실행하면서 수집한 정보를 바탕으로, 자주 실행되는 코드$_{hot \space code}$를 더 효율적인 기계어로 변환한다. 예를 들어 Ignition이 특정 함수가 항상 숫자만 처리한다는 정보를 수집했다면, TurboFan은 이 함수를 숫자 연산에 최적화된 기계어로 만든다.
하지만 JavaScript는 동적 타입 언어이기 때문에, TurboFan의 최적화는 항상 추측을 기반으로 한다. 만약 이전과 다른 타입의 데이터가 들어오면, V8은 최적화된 코드를 폐기하고 다시 Ignition으로 실행을 전환한다. 이를 디옵티마이제이션$_{deoptimization}$이라고 한다.
TurboFan의 이런 투기적 최적화$_{speculative \space optimization}$는 위험을 감수하면서도 큰 성능 향상을 얻을 수 있는 방법이다. JavaScript의 유연성을 해치지 않으면서도 정적 타입 언어에 근접한 성능을 얻을 수 있게 된다.
메모리 관리와 가비지 컬렉션
V8은 실행 중인 프로그램의 메모리를 Resident Set이라고 부르고, 크게 스택과 힙으로 나뉜다. 스택은 함수 호출 정보나 원시값 같은 정적 데이터를 저장하고, 힙은 객체와 같은 동적 데이터를 저장한다. 힙은 다시 여러 영역으로 나뉘는데, 새로운 객체가 할당되는 New Space, 오래 살아남은 객체가 이동하는 Old Space, 크기가 큰 객체를 위한 Large Object Space, JIT 컴파일된 코드를 저장하는 Code Space 등이 있다.

V8은 메모리를 두 세대$_{generation}$로 구분해 관리한다. 새로 생성된 객체는 Young 세대(New Space)에 들어가고, 여기서 살아남은 객체는 Old 세대(Old Space)로 이동한다. 대부분의 객체가 생성 직후 짧은 시간 내에 필요 없어진다는 "세대별 가설"에 기반한다.
V8은 두 가지 가비지 컬렉션을 사용한다. Young 세대를 위한 Minor GC(Scavenger)와 전체 힙을 위한 Major GC(Mark-Compact)다. Minor GC는 Young 세대를 두 공간으로 나눠서 관리하며, 살아남은 객체를 다른 공간으로 복사하는 방식으로 동작한다. Major GC는 더 이상 사용되지 않는 객체를 표시하고, 이들이 사용하던 메모리를 회수하며 필요한 경우 메모리 조각 모음도 수행한다.
참고로 V8은 2016년부터 Orinoco 프로젝트를 통해 가비지 컬렉션을 점진적으로 개선했다. 초기에는 parallel compaction과 black allocation 같은 최적화를 도입했고, 2017년에는 Young 세대의 가비지 컬렉션을 병렬 처리할 수 있는 parallel Scavenger를 도입했다. 이런 최적화들을 통해 가비지 컬렉션으로 인한 메인 스레드의 일시 정지 시간을 크게 줄일 수 있었다.
V8의 코드 실행 단계
파싱과 AST 생성
JavaScript 코드가 실행되기 위해서는 먼저 V8이 이해할 수 있는 형태로 변환되어야 한다. V8의 파싱 과정은 여러 단계를 거치는데, 소스 코드가 AST$_{Abstract \space Syntax \space Tree}$로 변환되기까지의 과정을 살펴보자.
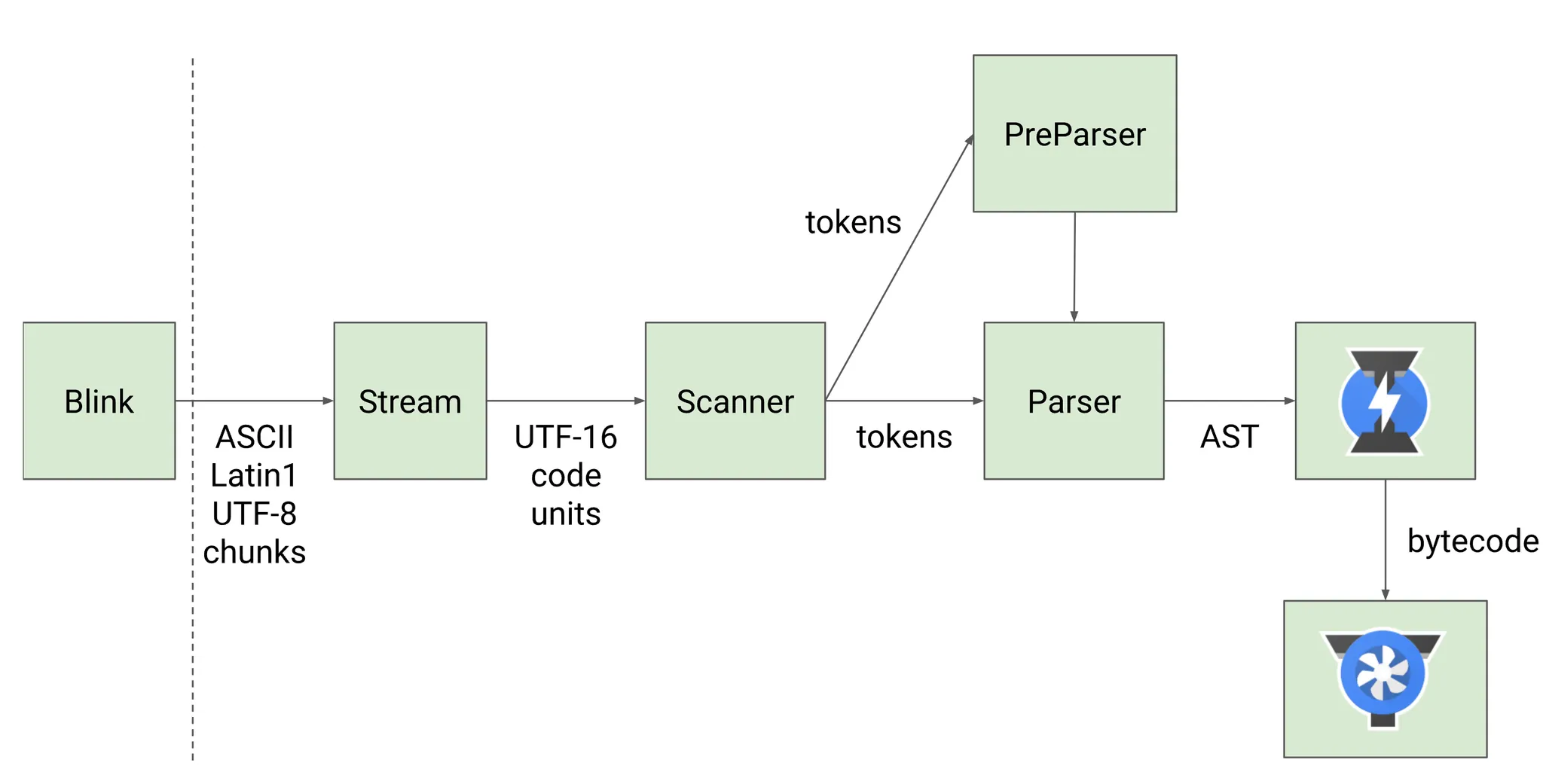
먼저 Blink 엔진이 소스 코드를 ASCII, Latin1, UTF-8 형식의 청크로 읽어들인다. 이 데이터는 스트림$_{Stream}$으로 전달되고, 스트림은 이를 UTF-16 코드 단위로 변환한다. 스캐너$_{Scanner}$는 이 UTF-16 코드 단위를 읽어 의미 있는 토큰으로 만든다. 예를 들어 'function'이라는 키워드나, '+'라는 연산자, 혹은 변수 이름 같은 식별자들이 토큰이 된다.
토큰이 만들어지면 V8은 PreParser와 Parser라는 두 가지 방식으로 처리한다. 이렇게 두 개의 파서를 사용하는 것은 V8의 지연 파싱 전략의 일부다.
지연 파싱$_{lazy \space parsing}$은 애플리케이션의 시작 시간을 단축하고 메모리 사용량을 줄여준다. PreParser는 당장 필요하지 않은 코드를 빠르게 검사만 하고 넘어가고, 실제로 그 코드가 필요할 때가 되어서야 완전한 파싱을 수행한다. 특히 중첩된 함수가 많은 코드에서 파싱 비용을 크게 줄여준다.
바이트코드 생성 과정
Parser가 만든 AST는 Ignition 인터프리터로 전달된다. Ignition은 이 AST를 바이트코드라고 부르는 중간 코드로 변환한다. 바이트코드는 AST보다 더 실행하기 좋은 형태로, 인터프리터가 이해하고 실행할 수 있는 저수준 명령어들의 시퀀스다.
이 과정에서 V8은 몇 가지 최적화를 수행한다. 예를 들어 const a = 1 + 2라는 코드를 바이트코드로 만들 때, V8은 미리 1 + 2를 계산해서 const a = 3으로 최적화할 수 있다. 또한 반복적으로 실행되는 코드를 더 효율적인 바이트코드로 변환하기도 한다.
바이트코드는 기계어보다 추상적이지만 AST보다는 구체적이다. 이런 중간 단계를 두는 이유는 다양한 CPU 아키텍처를 지원하면서도 실행 성능을 최적화하기 위해서다. 바이트코드는 나중에 TurboFan 컴파일러에 의해 실제 기계어로 변환될 수 있다.
JIT 컴파일과 최적화
V8의 Just-In-Time 컴파일은 JavaScript 코드를 실행하면서 필요한 시점에 기계어로 변환하는 방식이다. Ignition이 생성한 바이트코드는 처음에는 인터프리터에 의해 실행되지만, 자주 실행되는 코드$_{hot \space code}$를 발견하면 TurboFan 컴파일러가 최적화된 기계어로 변환한다.
최적화 과정에서 TurboFan은 타입 정보와 실행 패턴을 수집한다. 예를 들어 어떤 함수가 항상 숫자 타입의 인자를 받아 처리한다면, TurboFan은 이 함수를 숫자 연산에 특화된 기계어로 변환한다. 이는 JavaScript가 동적 타입 언어임에도 불구하고 정적 타입 언어에 근접한 성능을 낼 수 있게 해준다.
하지만 이런 최적화는 항상 안전하지는 않다. JavaScript의 동적 특성 때문에 기존 가정이 깨질 수 있기 때문이다. 이럴 때는 최적화된 코드를 폐기하고 다시 바이트코드로 돌아가야 하는데, 이를 디옵티마이제이션$_{deoptimization}$이라고 한다.
디옵티마이제이션이 발생하는 경우
디옵티마이제이션은 V8이 기존에 세웠던 가정이 더 이상 유효하지 않을 때 발생한다. TurboFan이 만든 최적화된 코드를 폐기하고 다시 Ignition의 바이트코드로 돌아가야 하는 상황을 살펴보자.
가장 흔한 경우는 타입이 변경될 때다.
function add(a, b) {
return a + b;
}
// 항상 숫자만 전달했다면 TurboFan은 숫자 덧셈에 최적화된 코드를 생성
add(1, 2);
add(2, 3);
add(3, 4);
// 문자열이 전달되면 기존 최적화가 무효화됨
add("hello", "world");또 다른 경우는 객체의 구조가 변경될 때다. V8은 같은 구조를 가진 객체들을 효율적으로 처리하기 위해 hidden class라는 개념을 사용하는데, 객체에 새로운 속성을 추가하거나 속성의 타입이 변경되면 디옵티마이제이션이 발생할 수 있다.
V8의 최적화 기법들
히든 클래스와 인라인 캐싱
JavaScript는 객체의 속성을 딕셔너리처럼 다루지만 성능 면에서 비효율적일 수 있다. V8은 이 문제를 해결하기 위해 히든 클래스$_{hidden \space class}$라는 개념을 도입했다. 히든 클래스는 객체의 구조를 추적하는 내부 표현으로, 같은 구조를 가진 객체들이 이 정보를 공유할 수 있게 해준다.
히든 클래스는 DescriptorArray와 TransitionArray라는 두 가지 배열을 사용한다. DescriptorArray는 객체의 프로퍼티 목록과 각 프로퍼티의 정보(위치, 속성 등)를 저장한다. TransitionArray는 객체에 새로운 프로퍼티가 추가될 때 어떤 히든 클래스로 전환되어야 하는지를 추적한다. 예를 들어 빈 객체에 프로퍼티 x를 추가하면 새로운 히든 클래스로 전환되고, 여기에 다시 y를 추가하면 또 다른 히든 클래스로 전환된다.

V8은 히든 클래스와 함께 인라인 캐싱$_{Inline \space Caching}$이라는 최적화 기법도 사용한다. 인라인 캐싱은 객체의 프로퍼티를 찾는 위치 정보를 기억해두는 방식이다. 예를 들어 어떤 함수가 객체의 특정 프로퍼티에 반복적으로 접근한다면, V8은 이 프로퍼티의 위치를 캐싱해둔다. 같은 히든 클래스를 가진 객체가 이 함수를 호출할 때는 프로퍼티를 다시 찾지 않고 캐싱된 위치 정보를 사용해 프로퍼티 접근 속도를 크게 향상시킨다.
V8과 Node.js
V8이 Node.js의 성공에 미친 영향
V8의 가장 큰 특징은 브라우저와 독립적으로 동작할 수 있다는 점이다. 2009년 Node.js는 이 특징을 활용해 V8을 자신들의 JavaScript 엔진으로 선택했다. Node.js의 폭발적인 성장과 함께 V8은 브라우저를 넘어 서버 사이드에서도 대규모 JavaScript 코드를 실행하는 엔진이 됐다.
브라우저의 DOM이나 웹 플랫폼 API들은 V8과 분리되어 있었기 때문에, Node.js는 이들 대신 서버 환경에 필요한 새로운 API들을 제공할 수 있었다. V8의 영향력은 여기서 그치지 않았다. Electron 같은 프로젝트를 통해 데스크톱 애플리케이션도 V8을 기반으로 개발할 수 있게 됐다.
V8은 C++로 작성되어 맥, 윈도우, 리눅스 등 다양한 플랫폼에서 실행될 수 있으며, 지속적으로 성능이 개선되고 있다. 특히 2009년 이후 JavaScript가 단순한 폼 검증이나 간단한 스크립트를 넘어 수십만 줄의 코드를 실행하는 완전한 애플리케이션으로 발전하면서, V8의 JIT 컴파일 같은 최적화 기능은 Node.js의 성능 향상에 도움이 됐다.
Node.js에서의 V8 활용
Node.js는 V8의 다양한 기능을 API 형태로 제공한다. 특히 메모리 관리와 성능 모니터링을 위한 API들이 많은데, 예를 들어 v8.getHeapStatistics()나 v8.getHeapSnapshot()을 통해 V8의 힙 메모리 상태를 확인할 수 있다.
Node.js는 V8의 직렬화$_{Serialization}$ API도 제공한다. 이를 통해 JavaScript 객체를 바이너리 형태로 변환하거나 반대로 바이너리 데이터를 JavaScript 객체로 복원할 수 있다. 또한 Promise hooks API를 통해 Promise의 생명주기를 추적할 수 있고, GC Profiler를 통해 가비지 컬렉션의 동작을 모니터링할 수 있다.
V8의 Startup Snapshot API는 Node.js 애플리케이션의 시작 시간을 최적화하는 데 사용된다. 이를 통해 자주 사용되는 코드나 데이터를 미리 직렬화해두고, 애플리케이션 시작 시 빠르게 로드할 수 있다.
references
https://www.youtube.com/watch?v=xckH5s3UuX4&ab_channel=freeCodeCampTalks
https://medium.com/dailyjs/understanding-v8s-bytecode-317d46c94775
https://www.youtube.com/watch?v=sloddfX9jLE&ab_channel=JSConf
https://v8.dev/blog/launching-ignition-and-turbofan
https://v8.dev/blog/trash-talk
https://deepu.tech/memory-management-in-v8
https://v8.dev/blog/orinoco-parallel-scavenger
https://v8.dev/docs/hidden-classes
https://mathiasbynens.be/notes/shapes-ics
https://nodejs.org/ko/learn/getting-started/the-v8-javascript-engine
'Web, Front-end > JavaScript' 카테고리의 다른 글
| [JavaScript] 이벤트 루프(Event Loop)와 비동기 통신 (1) | 2025.02.01 |
|---|---|
| [JavaScript] 함수 레벨 스코프와 블록 레벨 스코프 (1) | 2025.01.30 |
| [JavaScript] 스코프 체인 (scope chain) (1) | 2025.01.26 |
| [JavaScript] 스코프(scope)란 (0) | 2025.01.25 |
| [Javascript] 이벤트 전파 (1) | 2024.08.27 |
컴퓨터 전공 관련, 프론트엔드 개발 지식들을 공유합니다. React, Javascript를 다룰 줄 알며 요즘에는 Typescript에도 관심이 생겨 공부하고 있습니다. 서로 소통하면서 프로젝트 하는 것을 즐기며 많은 대외활동으로 개발 능력과 소프트 스킬을 다듬어나가고 있습니다.
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[JavaScript] 이벤트 루프(Event Loop)와 비동기 통신](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FoddAw%2FbtsL3f5kEMY%2FQ8vfiTxnUiztyLyhW6gSlK%2Fimg.jpg)
![[JavaScript] 함수 레벨 스코프와 블록 레벨 스코프](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fd4WD2k%2FbtsL18ZtG4g%2Fx0QFb7Ccaksm1LKketTeR0%2Fimg.jpg)
![[JavaScript] 스코프 체인 (scope chain)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcnBQ9r%2FbtsL1elcQcR%2F0kR3PD3wiCj8M6QJG7JR51%2Fimg.jpg)
![[JavaScript] 스코프(scope)란](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbf9EXk%2FbtsL1gwtWfs%2FSqqf1OKYJVroj20ZpLi7m0%2Fimg.jpg)