![[CS50] 자료구조 - 연결 리스트](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Feih5K7%2FbtsH36CMJsr%2FRoOUrVZNfp2rF3sKAnEuhK%2Fimg.jpg)

연결 리스트 소개
데이터 구조는 컴퓨터 메모리를 더 효율적으로 관리하기 위해 새로 정의하는 구조체다.
일종의 메모리 레이아웃 또는 지도로 생각할 수 있다. 이번 포스팅에서는 데이터 구조 중 하나인 연결 리스트에 대해 알아보겠다.
배열에서는 각 인덱스의 값이 메모리상에서 연이어 저장되어 있다. 그러나 꼭 그럴 필요가 있을까?
각 값이 메모리상의 여러 군데 나뉘어져 있다고 하더라도 바로 다음 값의 메모리 주소만 기억하고 있다면 여전히 값을 연이어서 읽어들일 수 있다. 이를 '연결 리스트'라고 한다.
아래 그림과 같이 크기가 3인 연결 리스트는 각 인덱스의 메모리 주소에서 자신의 값과 함께 바로 다음 값의 주소(포인터)를 저장한다.
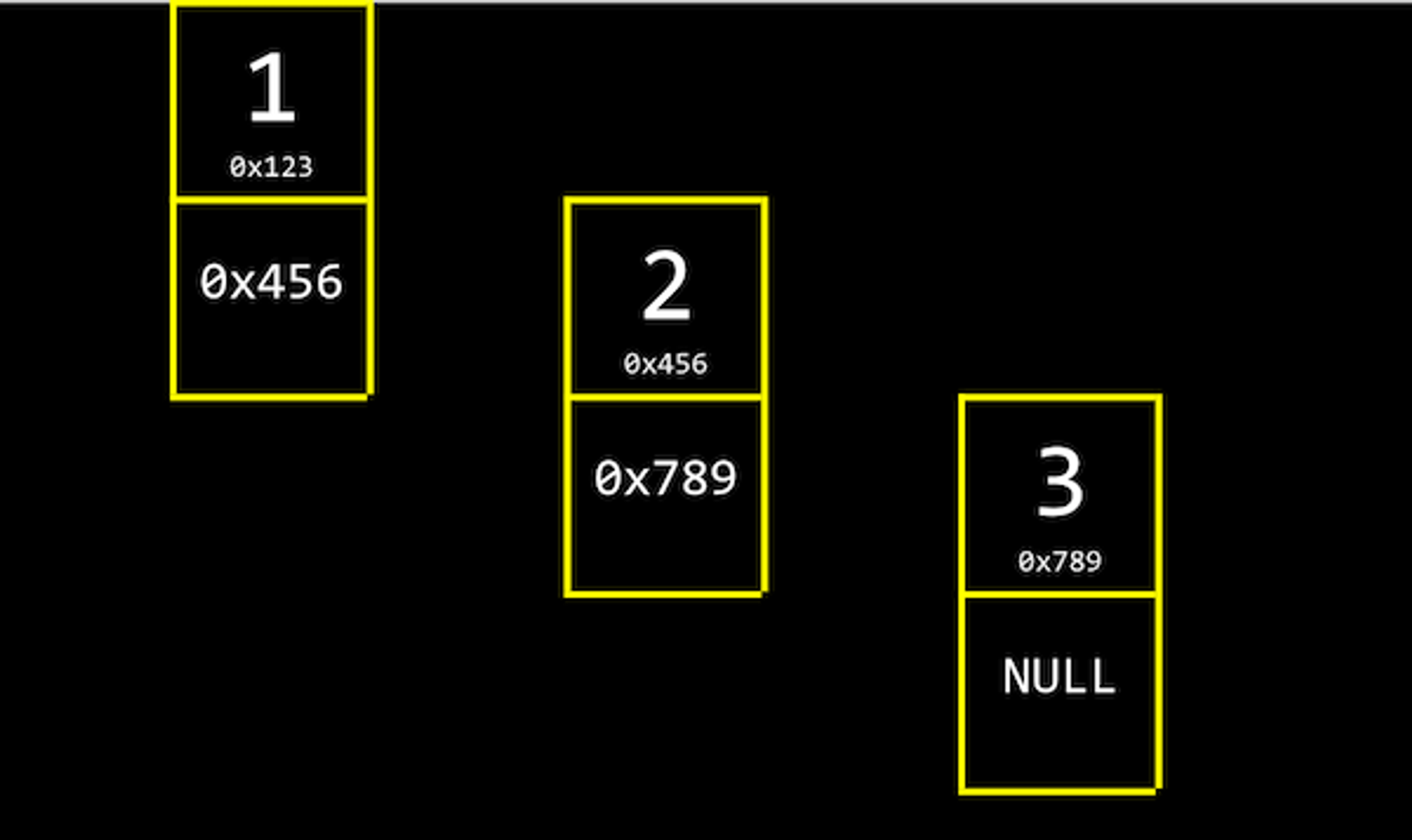
연결 리스트의 가장 첫 번째 값인 1은 2의 메모리 주소를, 2는 3의 메모리 주소를 함께 저장하고 있다.
3은 다음 값이 없기 때문에 NULL을 다음 값의 주소로 저장한다.
연결 리스트는 아래 코드와 같이 간단한 구조체로 정의할 수 있다.
typedef struct node
{
int number;
struct node *next;
}
node;위 코드에서 node라는 이름의 구조체는 number와 *next 두 개의 필드를 함께 정의하고 있다.
number는 각 노드가 가지는 값이고 *next는 다음 노드를 가리키는 포인터가 된다.
여기서 typedef struct 대신에 typedef struct node라고 'node'를 함께 명시해 주는 것은 구조체 안에서 node를 사용하기 위함이다.
연결 리스트 구현
앞서 정의한 구조체를 활용해 실제로 연결 리스트를 구현해보겠다.
#include <stdio.h>
#include <stdlib.h>
// 연결 리스트의 기본 단위가 되는 node 구조체 정의
typedef struct node
{
// node 안에서 정수형 값이 저장되는 변수 number
int number;
// 다음 node의 주소를 가리키는 포인터 *next
struct node *next;
}
node;
int main(void)
{
// list라는 이름의 node 포인터 정의, 연결 리스트의 첫 번째 node를 가리킴
// 이 포인터는 현재 아무 것도 가리키고 있지 않기 때문에 NULL로 초기화됨
node *list = NULL;
// 새로운 node를 위해 메모리를 할당하고 포인터 *n으로 가리
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 number 필드에 1의 값을 저장함. “n->number”는 “(*n).number”와 동일
// n이 가리키는 node의 number 필드를 의미함. 간단하게 화살표 표시 ‘->’로 쓸 수 있음
n->number = 1;
// n 다음에 정의된 node가 없으므로 NULL로 초기화함
n->next = NULL;
// 이제 첫 번째 node를 정의했기 때문에 list 포인터를 n 포인터로 바꿔 줌
list = n;
// 이제 list에 다른 node를 더 연결하기 위해 n에 새로운 메모리를 다시 할당함
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 number와 next의 값을 각각 저장함
n->number = 2;
n->next = NULL;
// list가 가리키는 것은 첫 번째 node, 이 node의 다음 node를 n 포인터로 지정
list->next = n;
// 다시 한 번 n 포인터에 새로운 메모리를 할당하고 number와 next의 값을 저장
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = 3;
n->next = NULL;
// 현재 list는 첫 번째 node를 가리키고 두 번째 node와 연결되어 있음
// 따라서 세 번째 node를 더 연결하기 위해 첫 번째 node (list)의 다음 node(list->next)의 다음 node(list->next->next)를 n 포인터로 지정
list->next->next = n;
// list에 연결된 node를 처음부터 방문하면서 각 number 값을 출력함
// 마지막 node의 next에는 NULL이 저장되어 있을 것이기 때문에 for 루프의 종료 조건이 됨
for (node *tmp = list; tmp != NULL; tmp = tmp->next)
{
printf("%i\\n", tmp->number);
}
// 메모리를 해제하기 위해 list에 연결된 node들을 처음부터 방문하면서 free 해줌
while (list != NULL)
{
node *tmp = list->next;
free(list);
list = tmp;
}
return 0;
}
연결 리스트로 트리 구현
트리는 연결 리스트를 기반으로 만들어진 데이터 구조다.
연결 리스트에서의 각 노드들의 연결이 1차원적으로 구성되어 있다면, 트리에서의 노드들의 연결은 2차원적으로 구성되어 있다고 볼 수 있다.
각 노드는 일정한 층에 속하고 다음 층의 노드들을 가리키는 포인터를 가지게 된다.
아래 그림은 트리의 한 예다. 나무가 거꾸로 뒤집혀 있는 형태를 생각하면 된다.
가장 높은 층에서 트리가 시작되는 노드를 '루트'라고 한다. 루트 노드는 다음 층의 노드들을 가리키고 있고 '자식 노드'라고 한다.
트리는 다양한 형태가 있지만 여기서는 '이진 검색 트리'에 대해 설명하겠다.
이진 검색 트리는 각 노드가 최대 두 개의 자식 노드를 가지는 구조다.
왼쪽 자식 노드는 부모 노드보다 작은 값을 가지고 오른쪽 자식 노드는 부모 노드보다 큰 값을 가진다.
이진 검색 트리의 노드 구조체 정의
typedef struct node
{
// 노드의 값
int number;
// 왼쪽 자식 노드
struct node *left;
// 오른쪽 자식 노드
struct node *right;
} node;number 필드는 노드의 값을 저장하고 left와 right 포인터는 각각 왼쪽과 오른쪽 자식 노드를 가리킨다.
이진 검색 함수 구현
이진 검색 트리에서 특정 값을 검색하는 함수를 구현해보자. 여기서는 50을 검색하는 예제를 다룬다.
#include <stdbool.h>
// 이진 검색 함수 (*tree는 이진 검색 트리를 가리키는 포인터)
bool search(node *tree)
{
// 트리가 비어있는 경우 'false'를 반환하고 함수 종료
if (tree == NULL)
{
return false;
}
// 현재 노드의 값이 50보다 크면 왼쪽 노드 검색
else if (50 < tree->number)
{
return search(tree->left);
}
// 현재 노드의 값이 50보다 작으면 오른쪽 노드 검색
else if (50 > tree->number)
{
return search(tree->right);
}
// 위 모든 조건이 만족하지 않으면 노드의 값이 50이므로 'true' 반환
else
{
return true;
}
}위 코드는 재귀적으로 트리를 순회하며 50을 검색한다.
트리가 비어 있으면 false를 반환하고 현재 노드의 값이 50보다 크면 왼쪽 서브트리를, 50보다 작으면 오른쪽 서브트리를 검색한다.
현재 노드의 값이 50과 같으면 true를 반환한다.
이진 검색 트리의 시간 복잡도
이진 검색 트리를 활용했을 때 검색 실행 시간과 노드 삽입 시간은 모두 O(log n)이다.
이는 트리가 균형 잡혀 있는 경우에 해당한다.
만약 트리가 한쪽으로 치우쳐진 경우(예: 모든 노드가 오른쪽 자식만 가진 경우), 최악의 경우 시간 복잡도는 O(n)이 될 수 있다.
이진 검색 트리 예제 코드
이진 검색 트리에서 값을 삽입하고 검색하는 전체적인 예제 코드를 작성해보겠다.
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
typedef struct node
{
int number;
struct node *left;
struct node *right;
} node;
// 새로운 노드를 생성하여 초기화하는 함수
node* create_node(int value)
{
node *new_node = malloc(sizeof(node));
if (new_node == NULL)
{
return NULL;
}
new_node->number = value;
new_node->left = NULL;
new_node->right = NULL;
return new_node;
}
// 트리에 값을 삽입하는 함수
bool insert(node **tree, int value)
{
if (*tree == NULL)
{
*tree = create_node(value);
return *tree != NULL;
}
if (value < (*tree)->number)
{
return insert(&(*tree)->left, value);
}
else if (value > (*tree)->number)
{
return insert(&(*tree)->right, value);
}
return false; // 값이 이미 존재하는 경우
}
// 트리의 메모리를 해제하는 함수
void free_tree(node *tree)
{
if (tree != NULL)
{
free_tree(tree->left);
free_tree(tree->right);
free(tree);
}
}
// 이진 검색 함수
bool search(node *tree, int value)
{
if (tree == NULL)
{
return false;
}
if (value < tree->number)
{
return search(tree->left, value);
}
else if (value > tree->number)
{
return search(tree->right, value);
}
else
{
return true;
}
}
int main(void)
{
node *tree = NULL;
// 값을 삽입
insert(&tree, 40);
insert(&tree, 20);
insert(&tree, 60);
insert(&tree, 10);
insert(&tree, 30);
insert(&tree, 50);
insert(&tree, 70);
// 값 검색
int search_value = 50;
if (search(tree, search_value))
{
printf("%d found in the tree.\\n", search_value);
}
else
{
printf("%d not found in the tree.\\n", search_value);
}
// 메모리 해제
free_tree(tree);
return 0;
}
이진 검색 트리에 값을 삽입하고 특정 값을 검색한 후 트리의 메모리를 해제한다.
insert 함수는 트리에 값을 삽입하며 search 함수는 값을 검색한다.
free_tree 함수는 재귀적으로 트리를 순회하며 메모리를 해제한다.
References
모두를 위한 컴퓨터 과학 (CS50 2019)
부스트코스 무료 강의
www.boostcourse.org
모두를 위한 컴퓨터 과학 (CS50 2019)
부스트코스 무료 강의
www.boostcourse.org
모두를 위한 컴퓨터 과학 (CS50 2019)
부스트코스 무료 강의
www.boostcourse.org
'CSE > CS 기초' 카테고리의 다른 글
| [CS50] 자료구조 - 트라이 (0) | 2024.06.18 |
|---|---|
| [CS50] 자료구조 - 해시 테이블 (0) | 2024.06.18 |
| [CS50] 자료구조 - 배열의 크기 조정하기 (0) | 2024.06.18 |
| [CS50] 자료구조 - malloc과 포인터 복습 (0) | 2024.06.18 |
| [CS50] 메모리 - 파일 쓰기 (0) | 2024.06.17 |
컴퓨터 전공 관련, 프론트엔드 개발 지식들을 공유합니다. React, Javascript를 다룰 줄 알며 요즘에는 Typescript에도 관심이 생겨 공부하고 있습니다. 서로 소통하면서 프로젝트 하는 것을 즐기며 많은 대외활동으로 개발 능력과 소프트 스킬을 다듬어나가고 있습니다.
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[CS50] 자료구조 - 트라이](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FrH2Qa%2FbtsH3nyiZ7i%2F4hTs7medvWGrG50KTVgYS1%2Fimg.jpg)
![[CS50] 자료구조 - 해시 테이블](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbOUDgT%2FbtsH3l8jCxG%2F2Uss4r7Kde6k3aBbR4T9e0%2Fimg.jpg)
![[CS50] 자료구조 - 배열의 크기 조정하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FqExQV%2FbtsH2R0Ecfp%2FmYwKcBtdH6utwlO9FA3Ot1%2Fimg.jpg)
![[CS50] 자료구조 - malloc과 포인터 복습](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fu4THG%2FbtsH3msyGNO%2FKT7jZFwXalh5MCG7g5qw31%2Fimg.jpg)