

본 게시글은 오라클로 배우는 데이터베이스 개론과 실습 2판 - 연습문제 4장 풀이입니다. 제가 이 책을 공부하면서 풀었던 풀이의 흔적이므로 정답이 아닐 수 있습니다. 혹여나 틀린 부분이 있어 오류를 댓글로 지적해주신다면 감사하겠습니다.
- 다음 내장 함수의 결과를 적으시오.
ABS(-15) : 15
CEIL(15.7) : 16
COS(3.14159) : -1
FLOOR(15.7) : 15
LOG(10,100) : 2
MOD(11,4) : 3
POWER(3,2) : 9
ROUND(15.7) : 16
SIGN(-15) : -1
TRUNC(15.7) : 15
CHR(67) : C
CONCAT('HAPPY','Birthday') : HAPPYBirthday
LOWER('Birthday') : birthday
LPAD('Page 1',15,'.') : .…*Page 1
LTRIM('Page 1','ae') : Page 1
REPLACE('JACK','J','BL') : BLACK
RPAD('Page 1',15,'.') : Page 1….*
RTRIM('Page 1','ae') : Page 1
SUBSTR('ABCDEFG',3,4) : CDEF
TRIM(LEADING 0 FROM '00AA00') : AA00
UPPER('Birthday') : BIRTHDAY
ASCII('A') : 65
INSTR('CORPORATE FLOOR', 'OR',3,2) : 14
LENGTH('Birthday') : 8
ADD_MONTHS('14/05/21',1) : 21/06/14
LAST_DAY(SYSDATE) : 2023-12-31
NEXT_DAY(SYSDATE,1) : 2023-12-11
ROUND(SYSDATE) : 2023-12-10
SYSDATE : 2023-12-10
TO_CHAR(SYSDATE) : 2023-12-10
TO_CHAR(123) : 123
TO_DATE('12 05 2014', 'DD MM YYYY') : 2014-05-12
TO_NUMBER('12.3') : 12.3
DECODE(1,1,'aa','bb') : aa
NULLIF(123,345) : 123
NVL(NULL,123) : 123
- 다음과 같이 Mybook 테이블을 생성한 후 NULL에 관한 SQL 문에 답하고, 결과를 보면서 NULL에 대한 개념도 정리해보시오.
| bookid | price |
|---|---|
| 1 | 10000 |
| 2 | 20000 |
| 3 | NULL |
(1)
SELECT * FROM Mybook;모든 레코드를 그대로 보여줌
(2)
SELECT bookid, NVL(price, 0) FROM Mybook;price가 NULL인 경우 0으로 치환하여 보여줌. NVL 함수는 첫 번째 인자가 NULL일 경우 두 번째 인자로 대체함
(3)
SELECT * FROM Mybook WHERE price IS NULL;price가 NULL인 레코드만 선택함. NULL은 =로 비교할 수 없으며 IS NULL을 사용해야 함
(4)
SELECT * FROM Mybook WHERE price=";오류가 발생함. NULL 값은 = 연산자로 비교할 수 없음
(5)
SELECT bookid, price+100 FROM Mybook;price가 NULL인 경우, 결과도 NULL이 됨. NULL에 어떤 값이 더해져도 NULL임
(6)
SELECT SUM(price), AVG(price), COUNT(*) FROM Mybook WHERE bookid >= 4;테이블에 bookid가 4 이상인 레코드가 없으므로, SUM과 AVG는 NULL을, COUNT는 0을 반환함
(7)
SELECT COUNT(*), COUNT(price) FROM Mybook;COUNT(*)는 테이블의 모든 레코드 수를 반환하고, COUNT(price)는 NULL이 아닌 price 레코드의 수를 반환함
(8)
SELECT SUM(price), AVG(price) FROM Mybook;SUM(price)는 NULL이 아닌 price 값의 합계를, AVG(price)는 NULL이 아닌 price 값의 평균을 반환합니다. NULL 값은 무시됨
- ROWNUM에 관한 다음 SQL 문에 답하시오. 데이터는 마당서점 데이터베이스를 이용한다.
(1)
SELECT * FROM Book;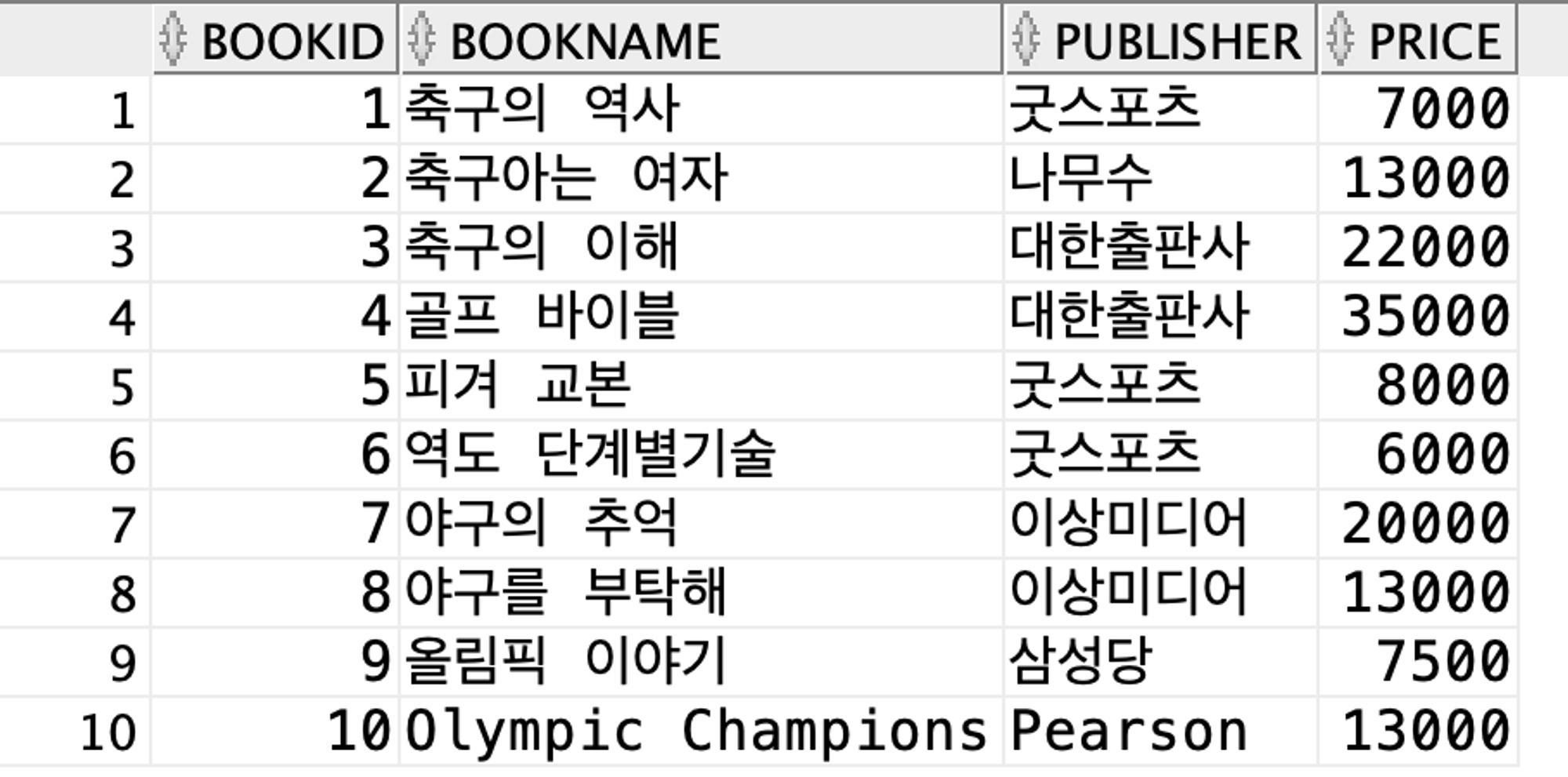
(2)
SELECT * FROM Book WHERE ROWNUM <= 5;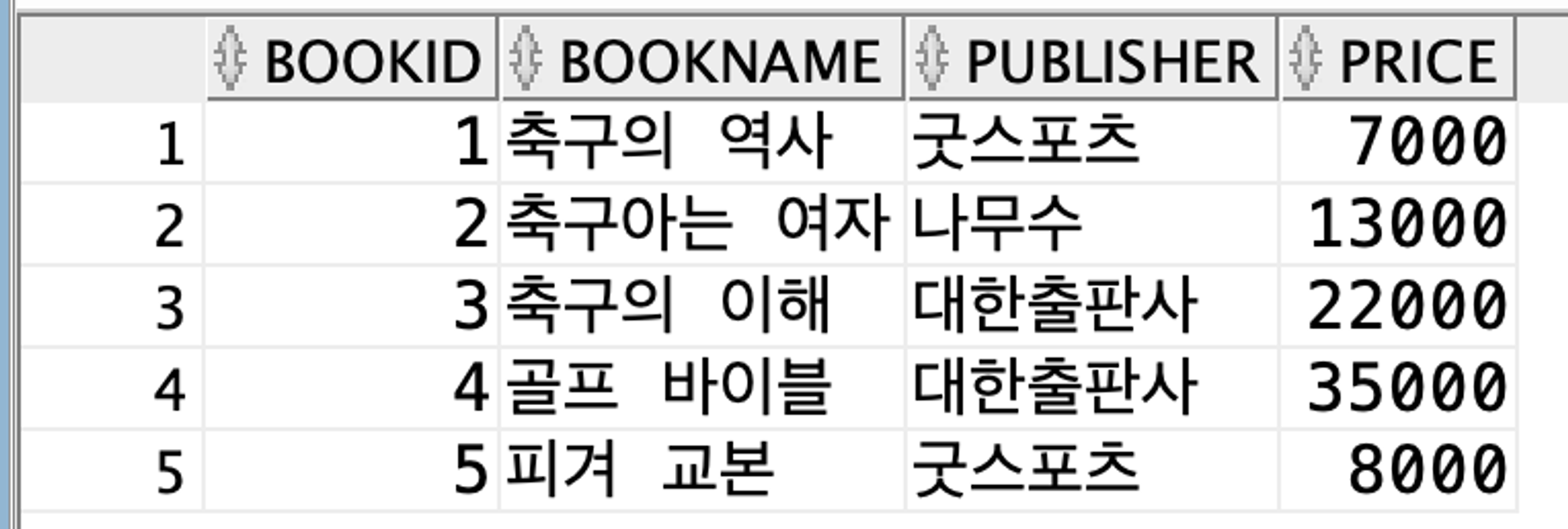
(3)
SELECT * FROM Book WHERE ROWNUM <= 5 ORDER BY price;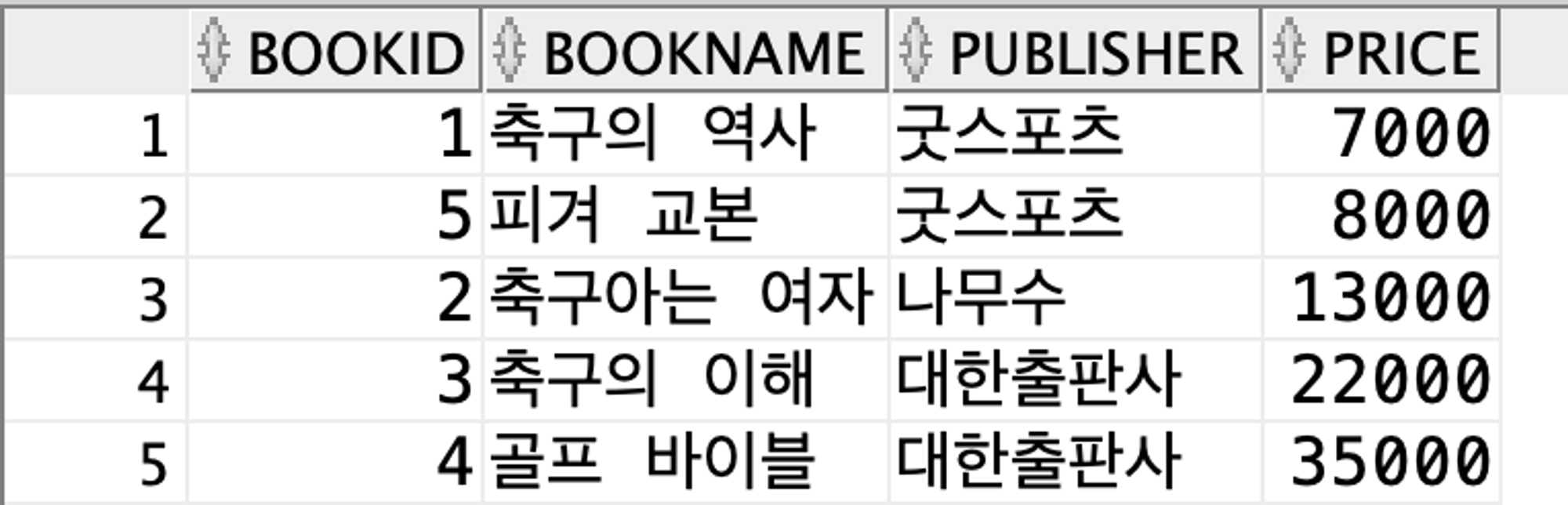
(4)
SELECT * FROM (SELECT * FROM Book ORDER BY price) b WHERE ROWNUM <= 5;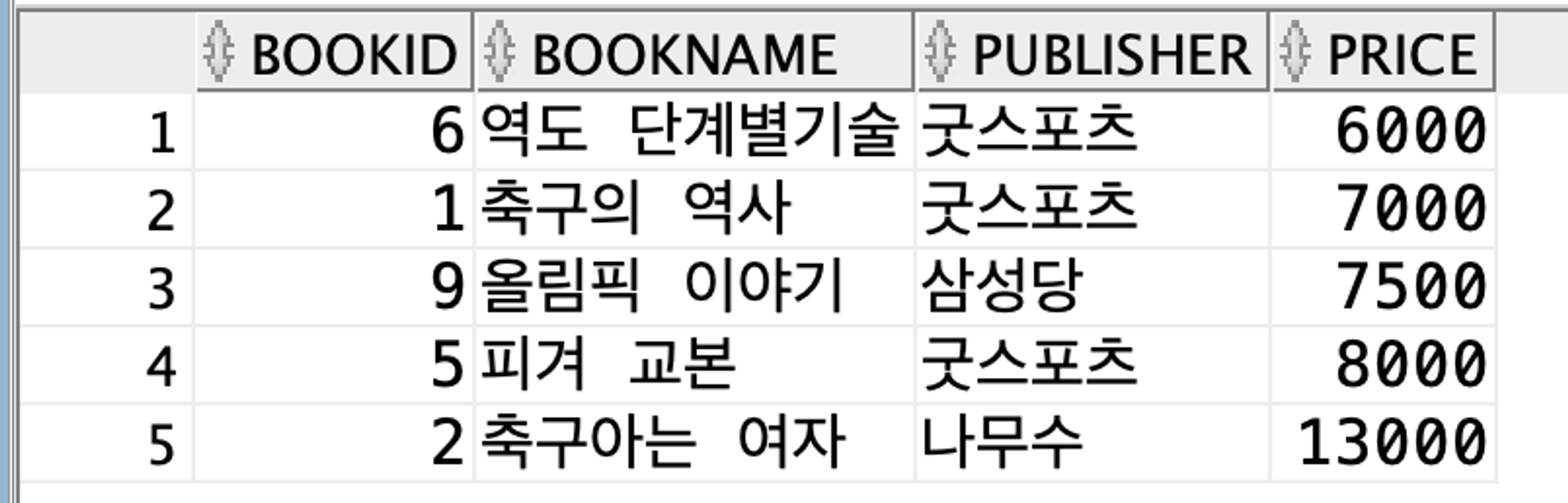
(5)
SELECT * FROM (SELECT * FROM Book WHERE ROWNUM <= 5) b ORDER BY price;
(6)
SELECT * FROM (SELECT * FROM Book WHERE ROWNUM <= 5 ORDER BY price) b;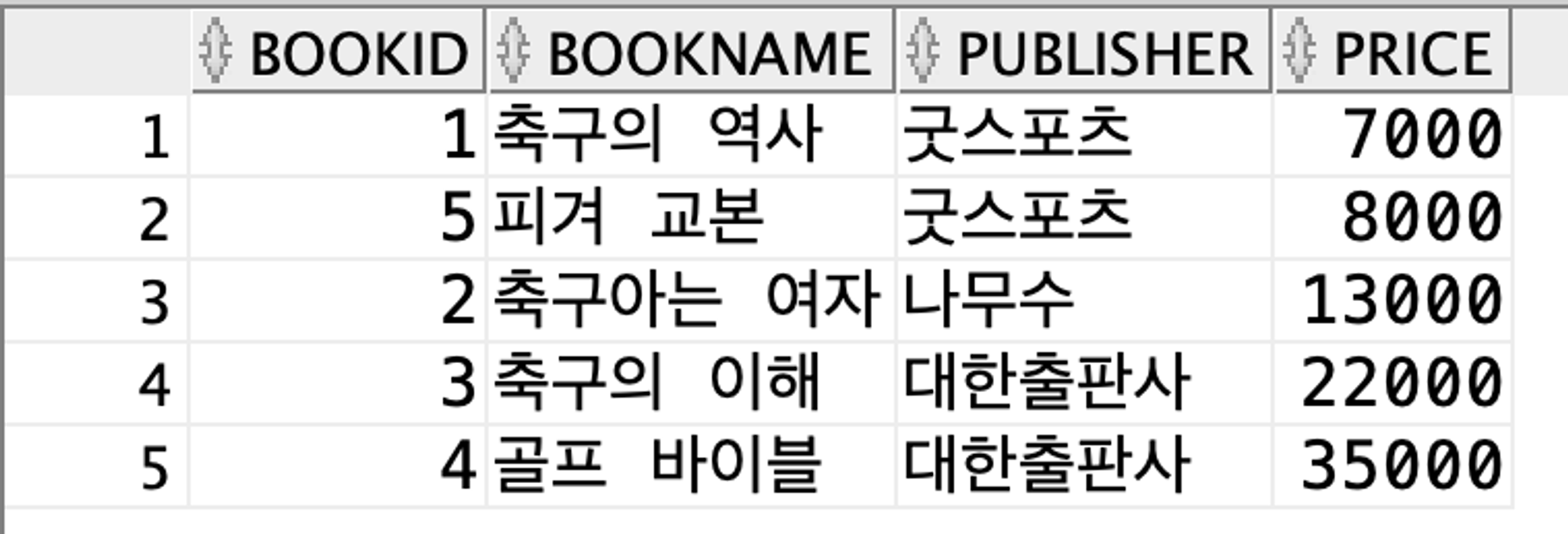
- 다음 과일(과일코드, 과일명) 테이블에 대한 SQL WHERE 문장 내의 비교조건을 해석한 것으로 옳지 않은 문장은 몇 개인가? (단, 밑줄은 기본키를 의미한다.)
| 과일코드 | 과일명 |
|---|---|
| 10 | 오렌지 |
| 15 | 키위 |
| 19 | 파인애플 |
| - “21 NOT IN (SELECT 과일코드 FROM 과일)”은 참이다. | |
| - “19 < ANY (SELECT 과일코드 FROM 과일)”은 거짓이다. | |
| - “15 < ALL (SELECT 과일코드 FROM 과일)”은 참이다. → ❌ |
```
ALL 연산자는 제공된 값이 서브쿼리의 모든 값보다 작을 경우 참임. 15는 테이블 내의 모든 과일코드 중 19보다 작으므로, 이 조건은 거짓임
```- “19 = ALL (SELECT 과일코드 FROM 과일)”은 거짓이다.
- 부속질의에 관한 다음 SQL 문을 수행해보고 어떤 질의에 대한 답인지 설명하시오.
(1)
SELECT custid, (SELECT address FROM Customer cs WHERE cs.custid = od.custid) "address", SUM(saleprice) "total"
FROM Orders od
GROUP BY od.custid;
고객별로 주문 총액과 해당 고객의 주소를 표시함
(2)
SELECT cs.name, s FROM (SELECT custid, AVG(saleprice) s FROM Orders GROUP BY custid) od, Customer cs
WHERE cs.custid = od.custid;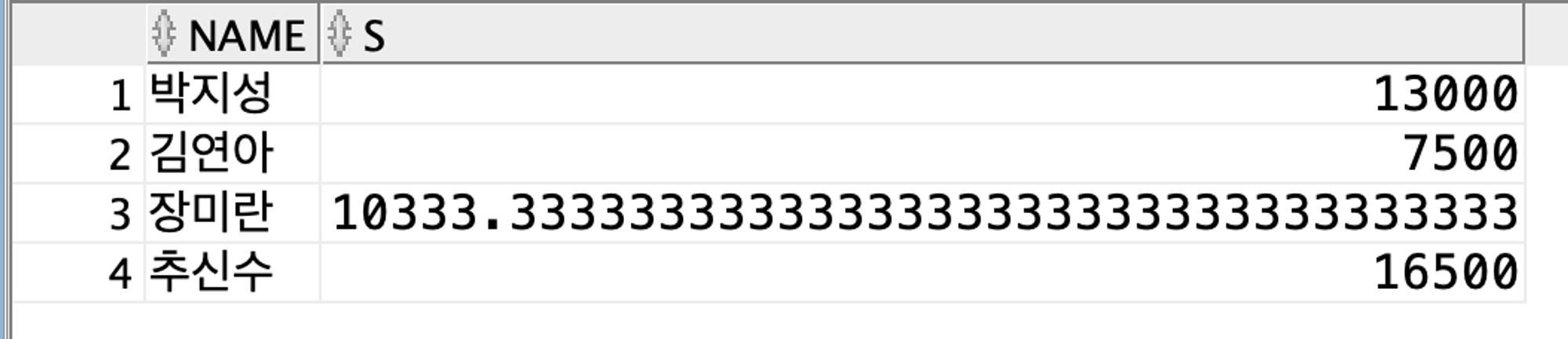
고객 이름과 해당 고객의 평균 주문 가격을 보여줌
(3)
SELECT SUM(saleprice) "total" FROM Orders od
WHERE EXISTS (SELECT * FROM Customer cs WHERE custid <= 3 AND cs.custid = od.custid);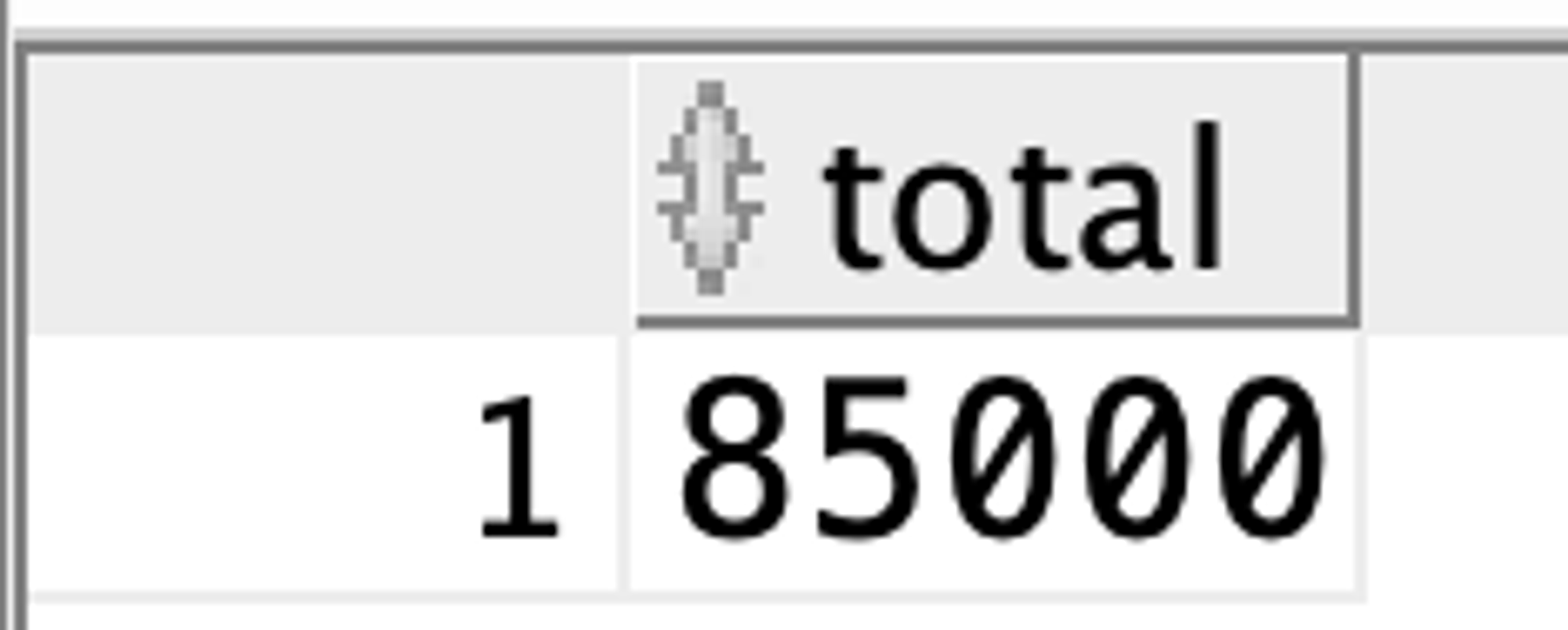
custid가 3 이하인 고객의 주문 총액을 반환함
- 뷰의 장점과 단점을 설명하시오.
view의 장점
- 보안 향상: 뷰를 사용하여 사용자가 접근할 수 있는 데이터를 제한할 수 있음. 특정 열이나 행만을 포함하는 뷰를 생성하여 민감한 데이터를 숨길 수 있음
- 복잡한 쿼리 단순화: 복잡한 쿼리를 뷰로 저장함으로써 사용자가 쉽게 데이터에 접근할 수 있도록 함
- 데이터 무결성 유지: 뷰를 통해 데이터를 수정하면 데이터의 무결성을 유지할 수 있음
- 로직 변경의 용이성: 데이터베이스 구조가 변경되더라도 뷰의 로직만 변경하면 되므로, 응용 프로그램 코드는 그대로 유지될 수 있음
view의 단점
- 성능 저하: 뷰는 실제 테이블의 데이터를 직접 저장하지 않으므로, 매번 쿼리를 실행할 때마다 데이터를 새로 계산해야 함
- 쓰기 작업 제한: 복잡한 쿼리로 생성된 뷰는 데이터를 수정하거나 추가하는 데 제한이 있을 수 있음
- 관리의 복잡성: 뷰가 서로 의존하는 경우 이들 간의 관계를 관리하는 것이 어려워질 수 있음
- 데이터베이스 설계 오해: 뷰가 실제 데이터의 구조를 숨길 수 있기 때문에, 사용자가 데이터베이스의 실제 설계를 잘못 이해할 수 있음
- SQL에서 뷰(view)의 역할에 대한 설명으로 옳지 않은 문장은 몇 개인가?
- 기본 테이블(base table)들만으로 작성된 질의를 간소화시킬 수 있다.
- 사용자의 접근권한에 따라 동일한 기본 테이블의 속성들을 선택적으로 제공할 수 있다.
- 기본 테이블들만으로 작성된 질의 처리 성능을 향상시키기 위해 개발되었다. → 뷰는 질의 처리 성능을 향상시키기 위해 개발된 것이 아니며, 때로는 뷰가 오히려 성능 저하를 일으킬 수 있음. 뷰의 주요 목적은 복잡한 쿼리의 간소화, 보안 향상, 데이터 무결성 유지 등임.
- 기본 테이블들의 물리적 구조를 변경시키지 않고 사용자가 원하는 새로운 가상 테이블을 생성시킬 수 있다.
- 마당서점 데이터베이스를 이용해 다음에 해당하는 뷰를 작성하시오.
(1) 판매가격이 20,000원 이상인 도서의 도서번호, 도서이름, 고객이름, 출판사, 판매가격을 보여주는 highorders 뷰를 생성하시오.
CREATE VIEW highorders AS
SELECT B.bookid, B.bookname, C.name AS customername, B.publisher, O.saleprice
FROM Book B
JOIN Orders O ON B.bookid = O.bookid
JOIN Customer C ON O.custid = C.custid
WHERE O.saleprice >= 20000;(2) 생성한 뷰를 이용하여 판매된 도서의 이름과 고객의 이름을 출력하는 SQL 문을 작성하시오.
SELECT bookname, customername FROM highorders;(3) highorders 뷰를 변경하고자 한다. 판매가격 속성을 삭제하는 명령을 수행하시오. 삭제 후 (2)번 SQL 문을 다시 수행하시오.
DROP VIEW highorders;
CREATE VIEW highorders AS
SELECT B.bookid, B.bookname, C.name AS customername, B.publisher
FROM Book B
JOIN Orders O ON B.bookid = O.bookid
JOIN Customer C ON O.custid = C.custid
WHERE O.saleprice >= 20000;
- [사원 데이터베이스] 3장의 연습문제 14번의 데이터베이스를 이용하여 다음 질의에 해당되는 SQL 문을 작성하시오.
(1) 팀장(mgr)이 없는 직원의 이름을 보이시오.
SELECT ename FROM Emp WHERE mgr IS NULL;(2) 사원의 이름과 부서의 이름을 보이시오(조인/스칼라 부속질의 사용)
SELECT E.ename, D.dname
FROM Emp E
JOIN Dept D ON E.deptno = D.deptno;(3) ‘CHICAGO’에 근무하는 사원의 이름을 보이시오(조인/인라인 뷰/중첩질의/EXISTS 사용)
SELECT E.ename
FROM Emp E
JOIN Dept D ON E.deptno = D.deptno
WHERE D.loc = 'CHICAGO';SELECT ename
FROM Emp
WHERE deptno IN (SELECT deptno FROM Dept WHERE loc = 'CHICAGO');(4) 평균보다 급여가 많은 직원의 이름을 보이시오.
SELECT ename
FROM Emp
WHERE sal > (SELECT AVG(sal) FROM Emp);(5) 자기 부서의 평균보다 급여가 많은 직원의 이름을 보이시오(상관 부속질의 사용)
SELECT ename
FROM Emp
WHERE sal > (SELECT AVG(sal) FROM Emp);
- [극장 데이터베이스 뷰] 다음은 네 개의 지점을 둔 극장의 데이터베이스이다. 밑줄 친 속성은 기본키이다. 테이블을 보고 다음 뷰를 생성하시오.
극장(극장번호, 극장이름, 위치)
상영관(극장번호, 상영관번호, 영화제목, 가격, 좌석수)
예약(극장번호, 상영관번호, 고객번호, 좌석번호, 날짜)
고객(고객번호, 이름, 주소)(1) 극장이름과 고객이름을 저장하는 극장-고객 뷰를 생성하시오.
CREATE VIEW 극장_고객 AS
SELECT 극장.극장이름, 고객.이름
FROM 극장
JOIN 상영관 ON 극장.극장번호 = 상영관.극장번호
JOIN 예약 ON 상영관.극장번호 = 예약.극장번호 AND 상영관.상영관번호 = 예약.상영관번호
JOIN 고객 ON 예약.고객번호 = 고객.고객번호;(2) ‘대한’극장에 예약을 한 고객의 수를 날짜별로 저장하는 대한-고객수 뷰를 생성하시오.
CREATE VIEW 대한_고객수 AS
SELECT 예약.날짜, COUNT(고객.고객번호) AS 고객수
FROM 극장
JOIN 예약 ON 극장.극장번호 = 예약.극장번호
WHERE 극장.극장이름 = '대한'
GROUP BY 예약.날짜;
- 10번의 극장 데이터베이스에 대하여 다음과 같은 뷰를 생성하였다. (1)~(6)의 질의가 의미가 있는지 판단하고 질의 결과가 어떤 내용인지 설명하시오.
CREATE VIEW 극장예약(극장이름, 예약수)
AS SELECT A.극장이름, COUNT(*)
FROM 극장 A, 예약 B
WHERE A.극장번호=B.극장번호
GROUP BY A.극장이름;(1) SELECT * FROM 극장예약;
→ 각 극장의 이름과 해당 극장에서의 총 예약 수
(2) SELECT 예약수 FROM 극장예약 WHERE 극장이름=’강남’;
→ '강남' 극장의 예약 수
(3) SELECT MIN(예약수) FROM 극장예약;
→ 최소 예약 수
(4) SELECT COUNT(*) FROM 극장예약;
→ 극장의 총 수
(5) SELECT 극장이름 FROM 극장예약 WHERE 예약수 > 100;
→ 예약 수가 100을 넘는 극장의 이름
(6) SELECT 극장이름 FROM 극장예약 ORDER BY 예약수;
→ 예약 수에 따라 정렬된 극장의 이름
- 데이터베이스는 하드디스크에 저장된다. 하드디스크에서 데이터를 읽어오는 데 걸리는 시간(액세스 시간)은 어떻게 구성되는지 설명하시오.
- 시크 타임: 하드디스크의 읽기/쓰기 헤드가 원하는 데이터가 저장된 디스크의 트랙(원반의 특정 원주)으로 이동하는 데 걸리는 시간
- 회전 지연: 디스크가 회전하여 원하는 데이터가 헤드 아래에 위치하게 되기까지의 시간
- 데이터 전송 시간: 실제 데이터가 디스크에서 컴퓨터의 RAM으로 이동하는 데 걸리는 시간
- B-tree는 균형 잡힌 트리를 말한다. 차수가 3인 비어 있는 B-tree에 1부터 9까지 삽입해보고 균형을 어떻게 유지하는지 설명하시오(위키피디아의 B-tree를 참조해본다).
(1) 비어 있는 트리에 처음으로 1을 삽입함
[1](2) 1 다음에 2를 삽입함
[1, 2](3) 노드가 차수를 초과하여 3을 삽입하면 분할이 발생함
[2]
/ \
[1] [3](4) 3의 오른쪽에 4를 삽입함
[2]
/ \
[1] [3, 4](5) 3과 4 사이에 5를 삽입하면 분할이 다시 발생함
[2]
/ \
[1] [3, 4](6) 5의 오른쪽에 6을 삽입함
[2, 4]
/ | \
[1] [3] [5, 6](7) 5와 6 사이에 7을 삽입하면 분할이 발생함
[2, 4, 6]
/ | | \
[1] [3] [5] [7](8) 7의 오른쪽에 8을 삽입함
[2, 4, 6]
/ | | \
[1] [3] [5] [7, 8](9) 7과 8 사이에 9를 삽입하면 분할이 발생함
[4]
/ \
[2] [6]
/ \ / \
[1] [3] [5] [7, 8, 9]이 때 분할로 인해 7, 8, 9 중 가운데 값인 8이 상위 노드로 이동하고, 노드가 재배열됨
[4, 8]
/ | \
[2] [6] [9]
/ \ | |
[1] [3] [5] [7]이 과정을 통해 B-tree는 항상 균형을 유지함. 노드가 차수를 초과할 때마다 분할을 통해 트리의 균형을 맞추고, 모든 노드가 정렬된 상태를 유지함
- 다음 데이터를 순차적으로 삽입하여 B-트리를 구성할 때 루트 노드에 존재하는 값은? (단, B-트리의 차수는 3이라고 가정한다.)
키 값들의 삽입 순서: 8, 5, 1, 7, 3, 12, 9, 6 [5, 7]
/ | \
[3] [6] [9]
/ \ / \
[1] [3] [8] [9, 12]
- 3장의 연습문제 14번 사원 데이터베이스를 이용하여 다음의 뷰를 생성하시오. 뷰를 이용하여 또 다른 뷰를 정의할 수 있는지 다음 SQL 문을 실행해 보고 결과를 보이시오.
CREATE VIEW SalesmanView
AS SELECT e.empno, e.ename, e.sal, d.dname
FROM Emp e, Dept d
WHERE e.deptno=d.deptno AND job='SALESMAN';
SELECT empno, ename, sal
FROM SalesmanView
WHERE ROWNUM <= 3;
CREATE VIEW SalesTop
AS SELECT empno, ename, sal, dname
FROM SalesmanView
WHERE sal >= 1500;
SELECT *
FROM SalesTop;(1) 상위 3명의 영업사원 정보를 조회함. 첫 번째, 두 번째, 세 번째 영업사원의 사원번호, 이름, 급여 정보를 보여줌
(2) 급여가 1500 이상인 영업사원의 사원번호, 이름, 급여, 부서 이름을 보여줌
- 마당서점 데이터베이스에서 다음 SQL 문을 수행하고 데이터베이스가 인덱스를 사용하는 과정을 확인해 보시오.
(1) 다음 SQL 문을 수행해본다.
SELECT name, address FROM Customer WHERE name LIKE '박세리';
(2) 실행 계획을 살펴본다. 실행 계획은 F10 키를 누른 후 [계획 설명] 탭을 선택하면 표시된다.
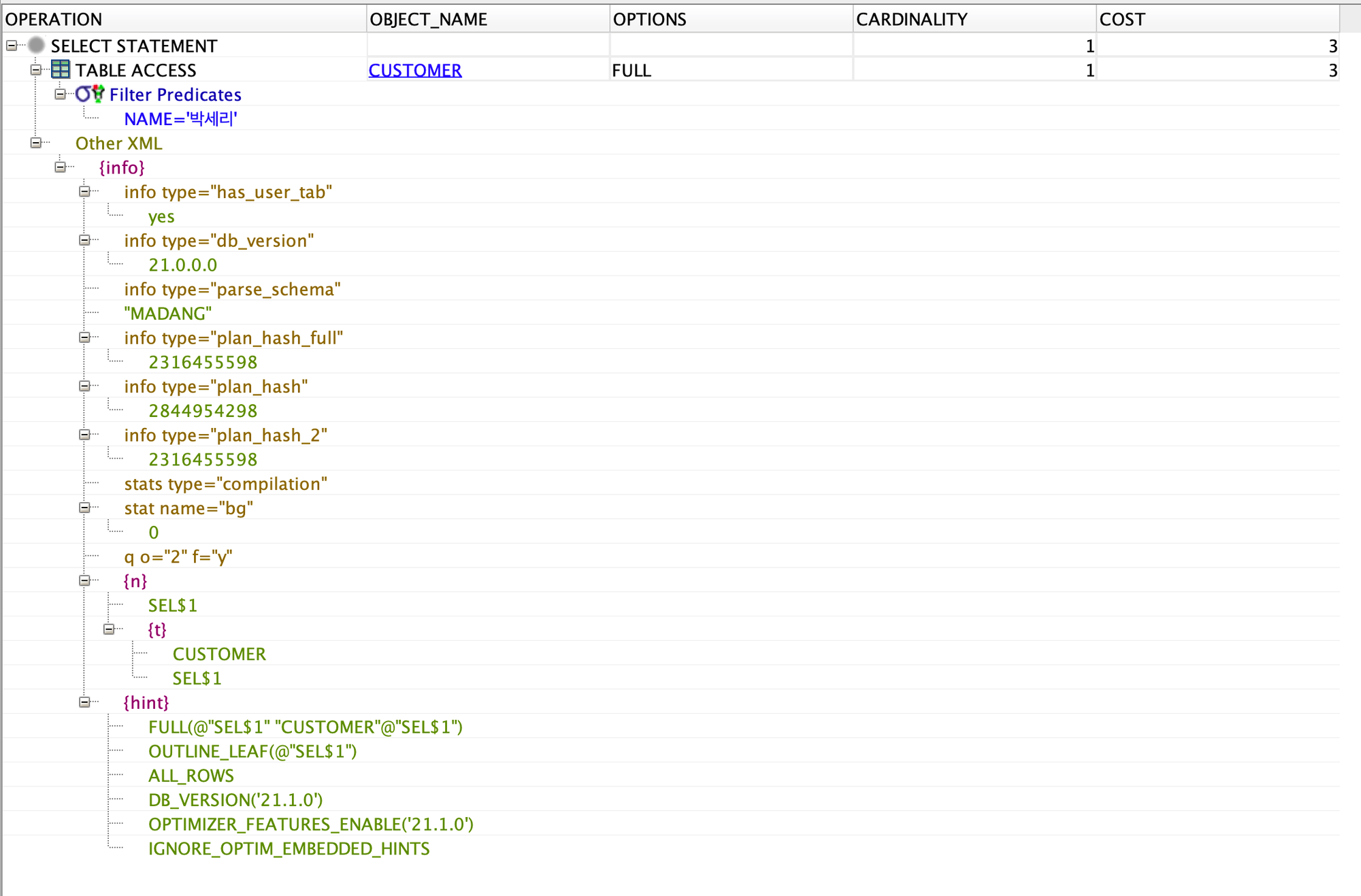
(3) Customer 테이블에 name으로 인덱스를 생성하시오. 생성 후 (1)번의 SQL 문을 다시 수행하고 실행 계획을 살펴보시오.
CREATE INDEX idx_name ON Customer(name);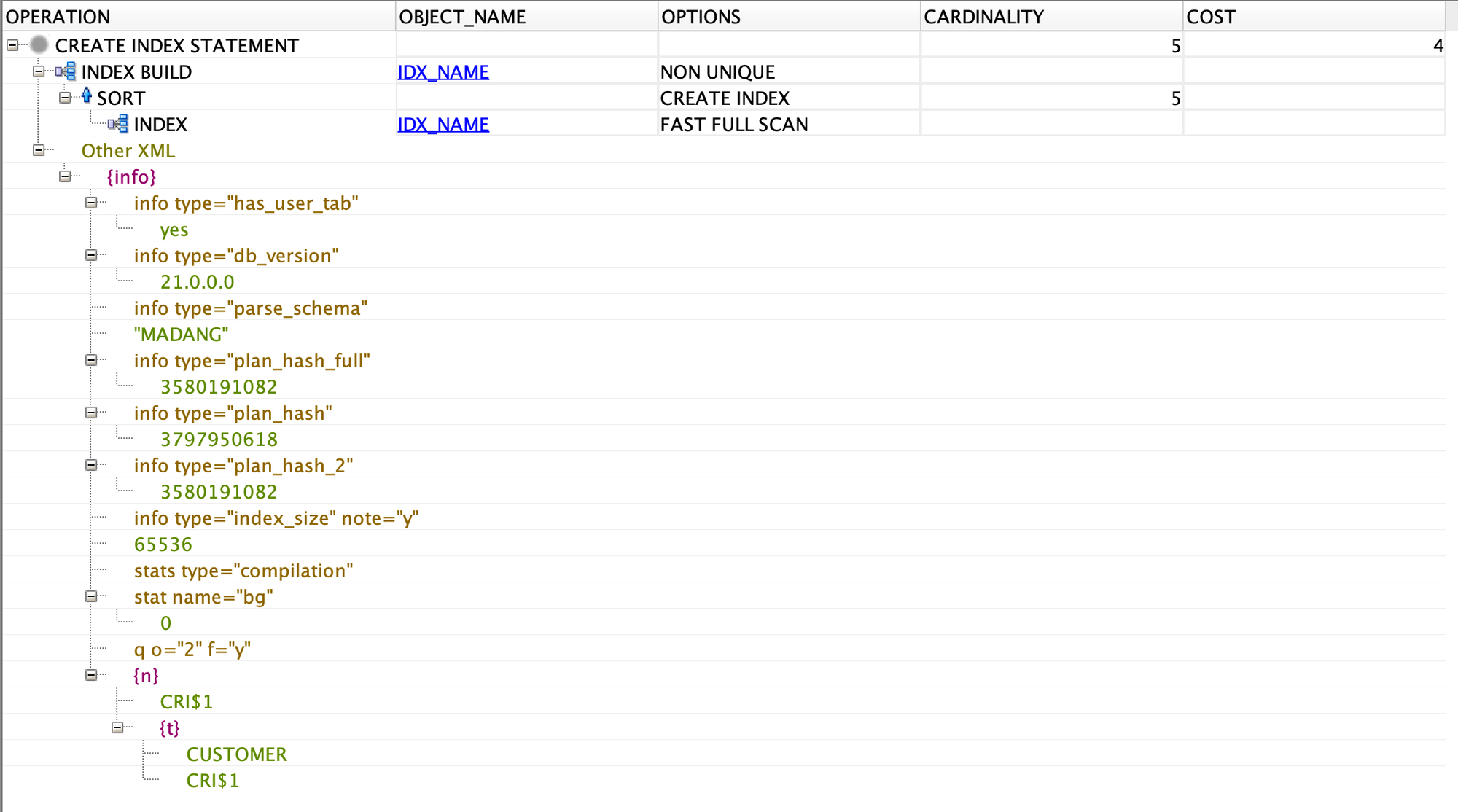
(4) 같은 질의에 대한 두 가지 실행 계획을 비교해 보시오.
인덱스가 있는 경우에는 데이터베이스가 전체 테이블 스캔 대신 인덱스 스캔을 수행하여 검색 효율이 크게 향상될 것임. 이는 검색 속도와 리소스 사용 측면에서 효율적임
(5) (3)번에서 생성한 인덱스를 삭제하시오.
DROP INDEX idx_name;'CSE > 데이터베이스 (database)' 카테고리의 다른 글
| 오라클로 배우는 데이터베이스 개론과 실습 2판 - 연습문제 5장 (0) | 2023.12.17 |
|---|---|
| 오라클로 배우는 데이터베이스 개론과 실습 2판 - 마당서점 데이터베이스 구축 (0) | 2023.12.16 |
| 오라클로 배우는 데이터베이스 개론과 실습 2판 - 연습문제 3장 (0) | 2023.09.11 |
| 오라클로 배우는 데이터베이스 개론과 실습 2판 - 연습문제 2장 (2023. 10. 26 수정) (2) | 2023.09.11 |
| 오라클로 배우는 데이터베이스 개론과 실습 2판 - 연습문제 1장 (2) | 2023.09.09 |
컴퓨터 전공 관련, 프론트엔드 개발 지식들을 공유합니다. React, Javascript를 다룰 줄 알며 요즘에는 Typescript에도 관심이 생겨 공부하고 있습니다. 서로 소통하면서 프로젝트 하는 것을 즐기며 많은 대외활동으로 개발 능력과 소프트 스킬을 다듬어나가고 있습니다.
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!



